Prisma ORMを選ぶ理由
このページでは、Prisma ORMの採用理由と、従来のORMやSQLクエリビルダーといった他のデータベースツールとの比較について説明します。
リレーショナルデータベースとの連携は、アプリケーション開発における主要なボトルネックです。SQLクエリや複雑なORMオブジェクトのデバッグには、開発時間が何時間も費やされることがよくあります。
Prisma ORMは、データベースクエリを送信するためのクリーンで型安全なAPIを提供し、*通常のJavaScriptオブジェクト*を返すことで、開発者がデータベースクエリを簡単に理解できるようにします。
TLDR
Prisma ORMの主な目標は、アプリケーション開発者がデータベースを扱う際の生産性を向上させることです。Prisma ORMがこれを達成するいくつかの例を以下に示します。
- オブジェクトで考える(リレーショナルデータのマッピングではなく)
- クラスではなくクエリ(複雑なモデルオブジェクトを避けるため)
- データベースおよびアプリケーションモデルにおける唯一の信頼できる情報源
- 一般的な落とし穴やアンチパターンを防ぐ健全な制約
- 正しいことを簡単にできる抽象化(「成功の落とし穴」)
- コンパイル時に検証できる型安全なデータベースクエリ
- ボイラープレートが少ないため、開発者はアプリの重要な部分に集中できます
- ドキュメントを調べる必要がない代わりにコードエディタでの自動補完
このページの残りの部分では、Prisma ORMが既存のデータベースツールと比較してどうであるかについて説明します。
SQL、従来のORM、その他のデータベースツールの問題点
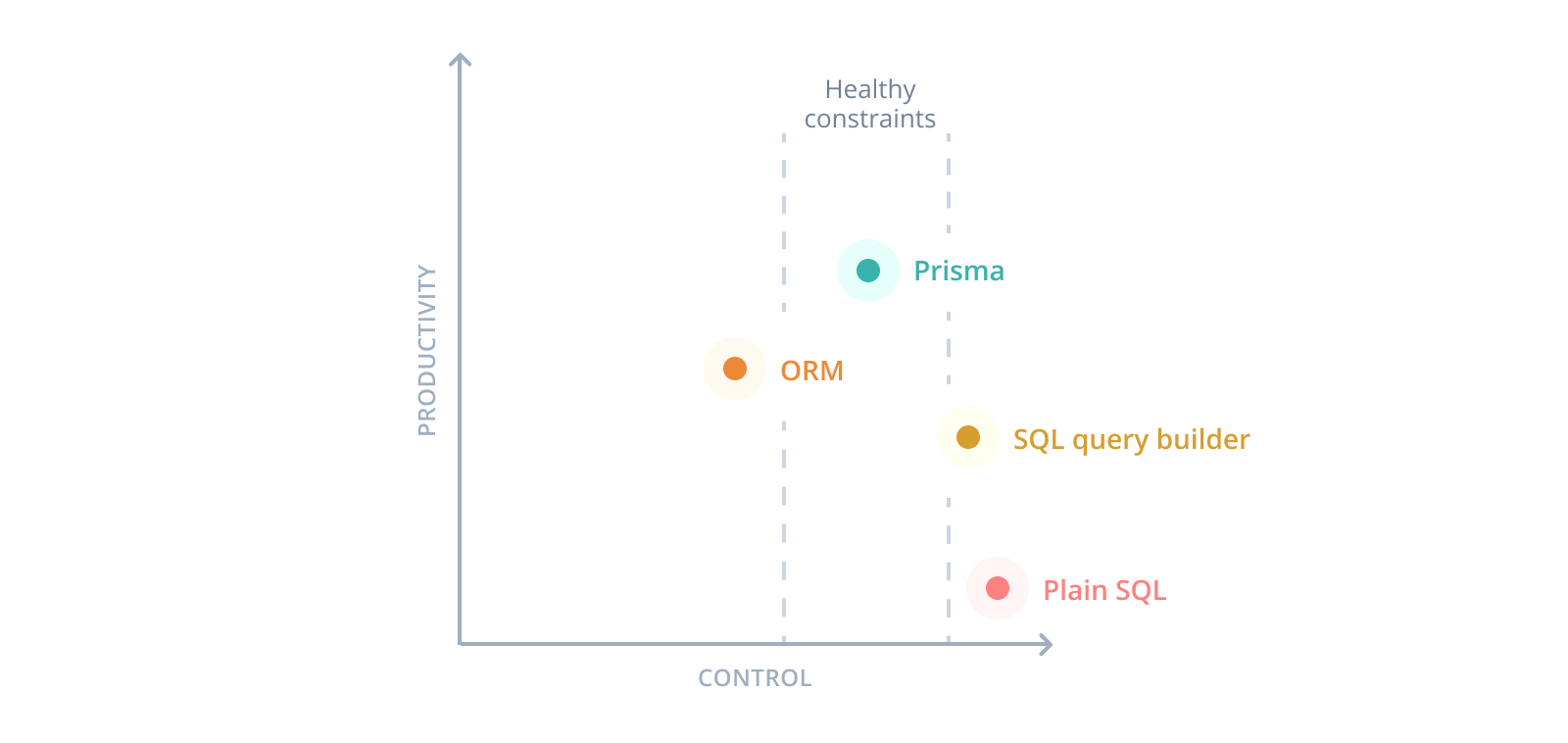
現在Node.jsとTypeScriptのエコシステムに存在するデータベースツールの主な問題は、生産性と制御の間の大きなトレードオフを必要とすることです。
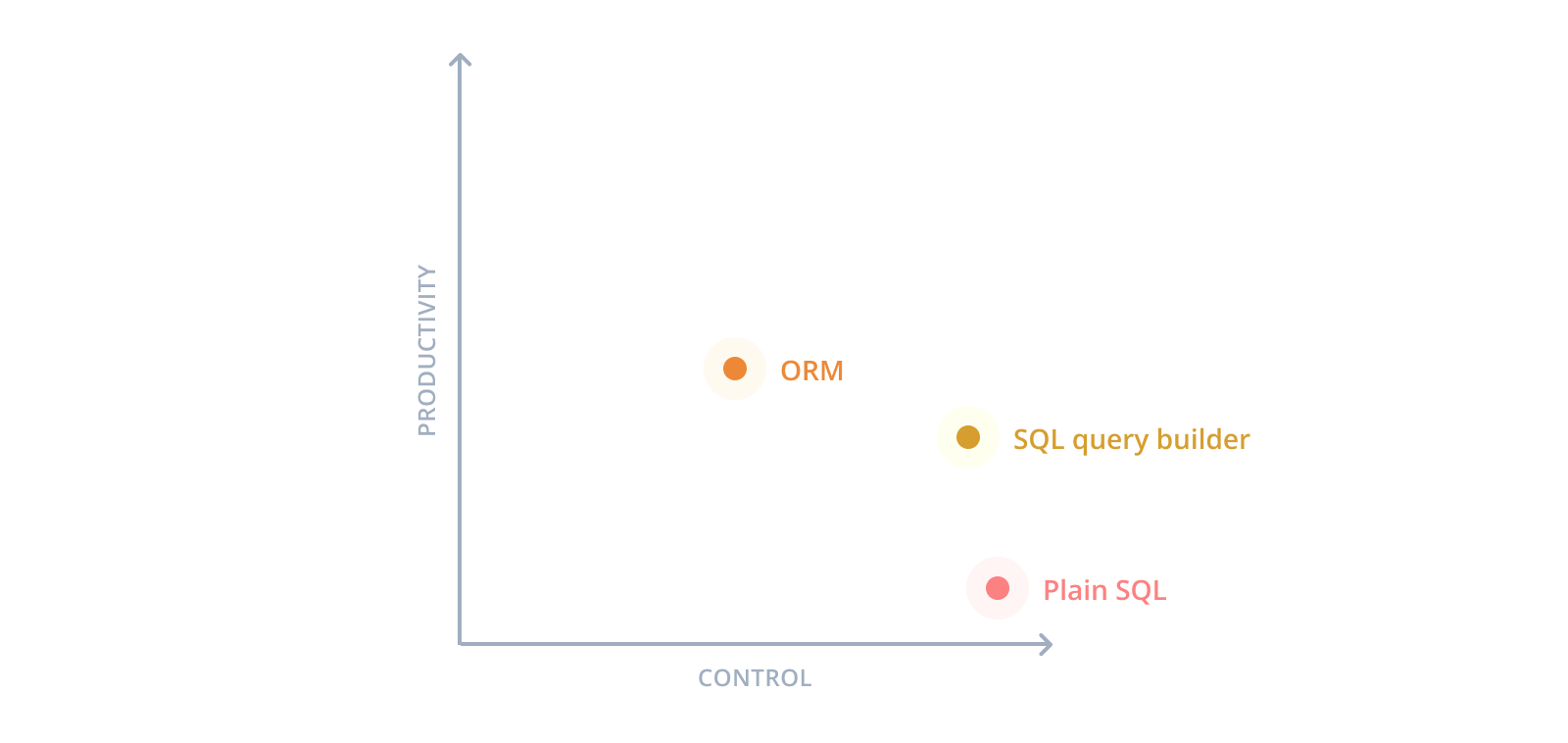
生のSQL:完全な制御、低い生産性
生のSQL(例えば、ネイティブのpgやmysql Node.jsデータベースドライバを使用する場合)では、データベース操作を完全に制御できます。しかし、プレーンなSQL文字列をデータベースに送信することは面倒で、多くのオーバーヘッド(手動の接続処理、繰り返し発生するボイラープレートなど)を伴うため、生産性が低下します。
このアプローチのもう一つの大きな問題は、クエリ結果に型安全性が得られないことです。もちろん、結果を手動で型付けすることはできますが、これは膨大な作業量であり、データベーススキーマやクエリを変更するたびに型定義を同期させるために大規模なリファクタリングが必要になります。
さらに、SQLクエリをプレーンな文字列として送信するということは、エディタで自動補完が効かないことを意味します。
SQLクエリビルダー:高い制御、中程度の生産性
高いレベルの制御を維持し、より良い生産性を提供する一般的な解決策は、SQLクエリビルダー(例:knex.js)を使用することです。このようなツールは、SQLクエリを構築するためのプログラム的な抽象化を提供します。
SQLクエリビルダーの最大の欠点は、アプリケーション開発者がまだSQLの観点でデータを考える必要があることです。これは、リレーショナルデータをオブジェクトに変換する認知的および実用的なコストを伴います。もう一つの問題は、SQLクエリで何をしているのかを正確に理解していないと、簡単に自滅してしまうことです。
従来のORM:少ない制御、高い生産性
従来のORMは、アプリケーションモデルをクラスとして定義することでSQLから抽象化します。これらのクラスはデータベースのテーブルにマッピングされます。
「オブジェクトリレーショナルマッパー(ORM)は、プログラマーの友(オブジェクト)とデータベースのプリミティブ(リレーション)の間のギャップを埋めるために存在します。これらの異なるモデルが存在する理由は、機能的な側面と同様に文化的な側面にもあります。プログラマーは、実行中のプログラムにおける単一のものの状態をカプセル化できるため、オブジェクトを好みます。データベースは、データセット全体の制約や、データセット全体への効率的なアクセスパターンにより適しているため、リレーションを好みます。」
その後、モデルクラスのインスタンスのメソッドを呼び出すことで、データを読み書きできます。
これははるかに便利で、開発者がデータについて考える際のメンタルモデルに近いです。しかし、落とし穴は何でしょうか?
「ORMは、最初は順調に進むが、時間が経つにつれて複雑になり、やがてユーザーを、明確な境界点、明確な勝利条件、明確な脱出戦略のない拘束に陥れる泥沼である。」
アプリケーション開発者として、データに対するメンタルモデルはオブジェクトです。一方、SQLにおけるデータのメンタルモデルはテーブルです。
これら2つの異なるデータ表現間の隔たりは、しばしばオブジェクトリレーショナルインピーダンスミスマッチと呼ばれます。オブジェクトリレーショナルインピーダンスミスマッチは、多くの開発者が従来のORMを好まない主要な理由でもあります。
例として、各アプローチでデータがどのように整理され、リレーションシップがどのように扱われるかを考えてみましょう。
- リレーショナルデータベース:データは通常、正規化され(フラットになり)、外部キーを使用してエンティティ間をリンクします。その後、実際の関係を明確にするためにエンティティをJOINする必要があります。
- オブジェクト指向:オブジェクトは深くネストされた構造であり、ドット表記を使用するだけで簡単にリレーションシップを辿ることができます。
これは、従来のORMにおける主な落とし穴の1つを示唆しています。おなじみのドット表記を使って簡単にリレーションシップを辿れるように見える一方で、内部ではORMがSQL JOINを生成しており、これはコストが高く、アプリケーションを劇的に遅くする可能性があります(この症状の1つがN+1問題です)。
結論として:従来のORMの魅力は、リレーショナルモデルを抽象化し、データを純粋にオブジェクトとして考えるという前提にあります。この前提自体は素晴らしいものですが、リレーショナルデータが簡単にオブジェクトにマッピングできるという誤った仮定に基づいており、これが多くの複雑さと落とし穴につながります。
アプリケーション開発者はデータに関心を持つべきであり、SQLではない
1970年代に開発されたにもかかわらず(!)、SQLは驚くべき方法で時の試練に耐えてきました。しかし、開発者ツールの進歩と近代化に伴い、SQLが本当にアプリケーション開発者が扱うのに最適な抽象化なのかを問う価値があります。
結局のところ、開発者は機能実装に必要なデータのみに関心を払うべきであり、複雑なSQLクエリを解明したり、ニーズに合わせてクエリ結果を加工したりするのに時間を費やすべきではありません。
アプリケーション開発においてSQLに反対する別の主張があります。SQLの力は、何をすべきかを正確に理解していれば恩恵となり得ますが、その複雑さは呪いとなり得ます。経験豊富なSQLユーザーでさえ予測に苦労するアンチパターンや落とし穴が数多く存在し、しばしばパフォーマンスや何時間ものデバッグ時間を犠牲にしています。
開発者は、SQLクエリで「正しいこと」をするかどうかを心配するのではなく、必要なデータを要求できるべきです。彼らのために正しい決定を下す抽象化を使用すべきです。これは、抽象化が開発者の間違いを防ぐ特定の「健全な」制約を課すことを意味する場合があります。
Prisma ORMは開発者の生産性を高める
Prisma ORMの主な目標は、アプリケーション開発者がデータベースを扱う際の生産性を向上させることです。生産性と制御の間のトレードオフを再度考慮すると、これがPrisma ORMがどのように適合するかを示しています。