モデル
Prismaスキーマのデータモデル定義部分は、アプリケーションのモデル(Prismaモデルとも呼ばれます)を定義します。モデルは
- アプリケーションドメインのエンティティを表します
- データベース内のテーブル(PostgreSQLのようなリレーショナルデータベース)またはコレクション(MongoDB)にマッピングされます
- 生成されたPrisma Client APIで利用可能なクエリの基盤を形成します
- TypeScriptと共に使用する場合、Prisma Clientはモデルとそのあらゆるバリエーションに対して生成された型定義を提供し、データベースアクセスを完全に型安全にします。
以下のスキーマはブログプラットフォームを記述しています - データモデル定義が強調表示されています
- リレーショナルデータベース
- MongoDB
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
bio String
user User @relation(fields: [userId], references: [id])
userId Int @unique
}
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
categories Category[]
}
model Category {
id Int @id @default(autoincrement())
name String
posts Post[]
}
enum Role {
USER
ADMIN
}
datasource db {
provider = "mongodb"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
model Profile {
id String @id @default(auto()) @map("_id") @db.ObjectId
bio String
user User @relation(fields: [userId], references: [id])
userId String @unique @db.ObjectId
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
categoryIDs String[] @db.ObjectId
categories Category[] @relation(fields: [categoryIDs], references: [id])
}
model Category {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String
postIDs String[] @db.ObjectId
posts Post[] @relation(fields: [postIDs], references: [id])
}
enum Role {
USER
ADMIN
}
データモデル定義は以下で構成されます
- モデル(
modelプリミティブ)は、モデル間のリレーションを含む多数のフィールドを定義します - Enums(
enumプリミティブ)(コネクタがEnumsをサポートしている場合) - 属性と関数は、フィールドとモデルの動作を変更します
対応するデータベースは次のようになります
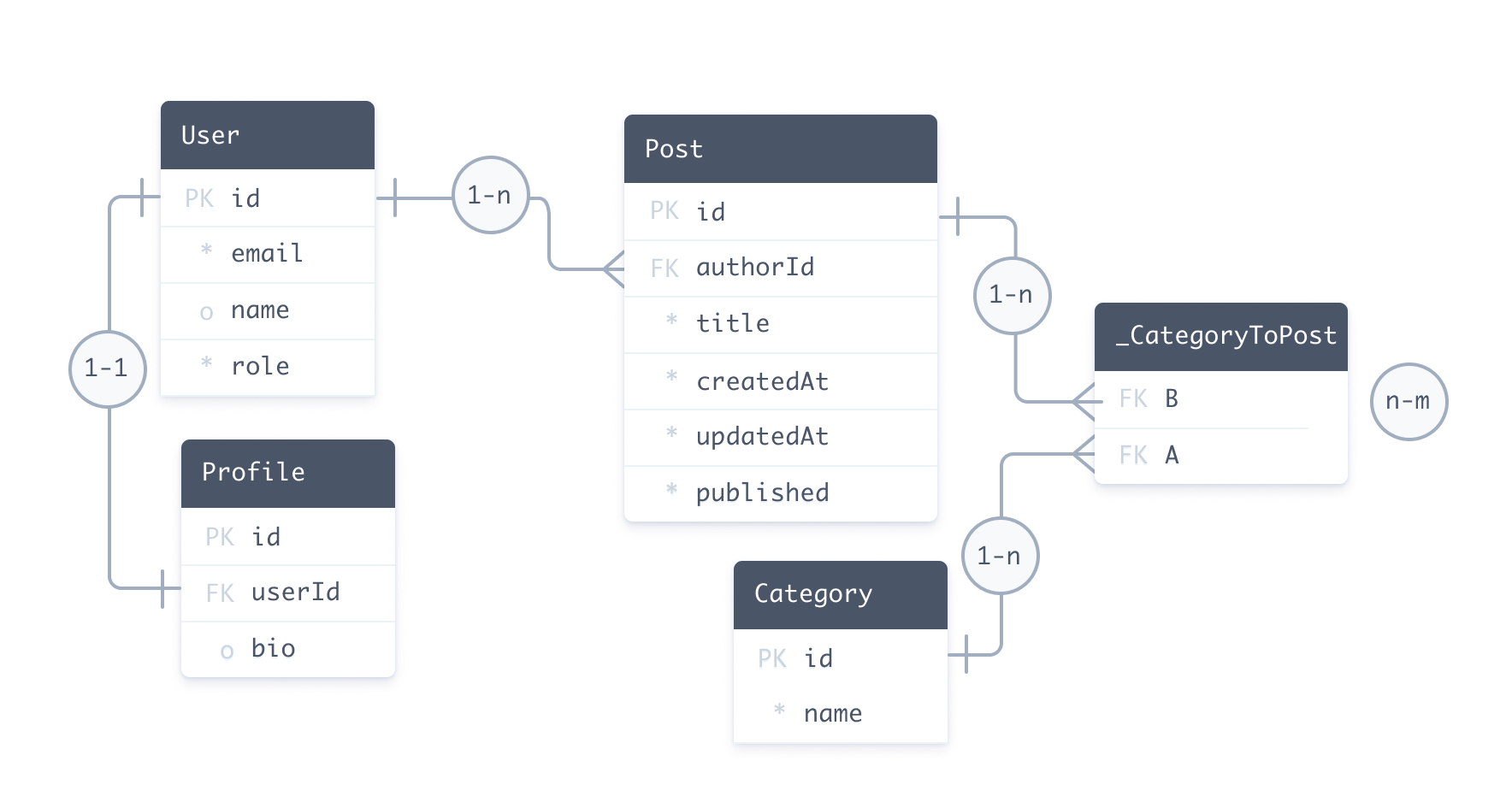
モデルはデータソースの基盤構造にマッピングされます。
- PostgreSQLやMySQLのようなリレーショナルデータベースでは、
modelはテーブルにマッピングされます - MongoDBでは、
modelはコレクションにマッピングされます
注:将来的には、非リレーショナルデータベースや他のデータソース用のコネクタが登場する可能性があります。例えば、REST APIの場合、リソースにマッピングされます。
以下のクエリは、このデータモデルから生成されたPrisma Clientを使用して作成します
Userレコード- ネストされた2つの
Postレコード - ネストされた3つの
Categoryレコード
- クエリ例
- コピー&ペースト例
const user = await prisma.user.create({
data: {
email: 'ariadne@prisma.io',
name: 'Ariadne',
posts: {
create: [
{
title: 'My first day at Prisma',
categories: {
create: {
name: 'Office',
},
},
},
{
title: 'How to connect to a SQLite database',
categories: {
create: [{ name: 'Databases' }, { name: 'Tutorials' }],
},
},
],
},
},
})
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient({})
// A `main` function so that you can use async/await
async function main() {
// Create user, posts, and categories
const user = await prisma.user.create({
data: {
email: 'ariadne@prisma.io',
name: 'Ariadne',
posts: {
create: [
{
title: 'My first day at Prisma',
categories: {
create: {
name: 'Office',
},
},
},
{
title: 'How to connect to a SQLite database',
categories: {
create: [{ name: 'Databases' }, { name: 'Tutorials' }],
},
},
],
},
},
})
// Return user, and posts, and categories
const returnUser = await prisma.user.findUnique({
where: {
id: user.id,
},
include: {
posts: {
include: {
categories: true,
},
},
},
})
console.log(returnUser)
}
main()
あなたのデータモデルは、あなたのアプリケーションドメインを反映します。例えば
- Eコマースアプリケーションでは、おそらく
Customer、Order、Item、Invoiceのようなモデルを持つでしょう。 - ソーシャルメディアアプリケーションでは、おそらく
User、Post、Photo、Messageのようなモデルを持つでしょう。
イントロスペクションとマイグレーション
データモデルを定義する方法は2つあります
- データモデルを手動で記述し、Prisma Migrateを使用する: データモデルを手動で記述し、Prisma Migrateを使用してデータベースにマッピングできます。この場合、データモデルがアプリケーションのモデルに対する唯一の真実のソースとなります。
- イントロスペクションによってデータモデルを生成する: 既存のデータベースがある場合や、SQLでデータベーススキーマを移行したい場合は、データベースをイントロスペクトすることでデータモデルを生成します。この場合、データベーススキーマがアプリケーションのモデルに対する唯一の真実のソースとなります。
モデルの定義
モデルはアプリケーションドメインのエンティティを表します。モデルはmodelブロックで表され、多数のフィールドを定義します。上記のデータモデル例では、User、Profile、Post、Categoryがモデルです。
ブログプラットフォームは以下のモデルで拡張できます
model Comment {
// Fields
}
model Tag {
// Fields
}
モデル名をテーブルまたはコレクションにマッピングする
Prismaモデルの命名規則(単数形、PascalCase)は、常にデータベースのテーブル名と一致するとは限りません。データベースでテーブル/コレクションに名前を付ける一般的なアプローチは、複数形とスネークケース記法を使用することです - 例えば:comments。commentsという名前のテーブルを持つデータベースをイントロスペクトすると、結果のPrismaモデルは次のようになります。
model comments {
// Fields
}
しかし、@@map属性を使用することで、基盤となるデータベースのcommentsテーブルの名前を変更せずに命名規則に準拠することができます。
model Comment {
// Fields
@@map("comments")
}
このモデル定義により、Prisma ORMは自動的にCommentモデルを基盤となるデータベースのcommentsテーブルにマッピングします。
注:列名または列挙値を
@mapすることも、列挙型名を@@mapすることもできます。
@mapと@@mapを使用すると、基盤となるデータベースのテーブル名と列名からモデル名とフィールド名を切り離すことで、Prisma Client APIの形状を調整できます。
フィールドの定義
モデルのプロパティはフィールドと呼ばれ、以下で構成されます
- フィールド名
- フィールド型
- オプションの型修飾子
- オプションの属性(ネイティブデータベース型属性を含む)
フィールドの型は、その構造を決定し、次の2つのカテゴリのいずれかに分類されます
- データベースの列(リレーショナルデータベース)またはドキュメントフィールド(MongoDB)にマッピングされるスカラー型(enumを含む) - 例:
StringまたはInt - モデル型(そのフィールドはリレーションフィールドと呼ばれます) - 例:
PostまたはComment[]。
以下の表は、サンプルスキーマのUserモデルのフィールドを記述しています
展開して表を見る
| 名前 | 型 | スカラー vs リレーション | 型修飾子 | 属性 |
|---|---|---|---|---|
id | Int | スカラー | - | @idと@default(autoincrement()) |
email | String | スカラー | - | |
name | String | スカラー | ? | - |
role | Role | スカラー(enum) | - | |
posts | Post | リレーション(Prismaレベルのフィールド) | [] | - |
profile | Profile | リレーション(Prismaレベルのフィールド) | ? | - |
スカラーフィールド
以下の例では、CommentとTagモデルをいくつかのスカラー型で拡張しています。いくつかのフィールドには属性が含まれます。
- リレーショナルデータベース
- MongoDB
model Comment {
id Int @id @default(autoincrement())
title String
content String
}
model Tag {
name String @id
}
model Comment {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String
content String
}
model Tag {
name String @id @map("_id")
}
スカラーフィールド型の完全なリストを参照してください。
リレーションフィールド
リレーションフィールドの型は別のモデルです - 例えば、投稿(Post)は複数のコメント(Comment[])を持つことができます
- リレーショナルデータベース
- MongoDB
model Post {
id Int @id @default(autoincrement())
// Other fields
comments Comment[] // A post can have many comments
}
model Comment {
id Int
// Other fields
post Post? @relation(fields: [postId], references: [id]) // A comment can have one post
postId Int?
}
model Post {
id String @id @default(auto()) @map("_id") @db.Objectid
// Other fields
comments Comment[] // A post can have many comments
}
model Comment {
id String @id @default(auto()) @map("_id") @db.Objectid
// Other fields
post Post? @relation(fields: [postId], references: [id]) // A comment can have one post
postId String? @db.ObjectId
}
モデル間の関係に関する詳細な例と情報については、リレーションのドキュメントを参照してください。
ネイティブ型マッピング
バージョン2.17.0以降では、基盤となるデータベースの型を記述するネイティブデータベース型属性(型属性)をサポートしています
model Post {
id Int @id
title String @db.VarChar(200)
content String
}
型属性は
- 基盤となるプロバイダーに固有です - 例えば、PostgreSQLは
Booleanに@db.Booleanを使用しますが、MySQLは@db.TinyInt(1)を使用します - PascalCaseで記述されます(例:
VarCharまたはText) @dbでプレフィックスされます。ここでdbはスキーマ内のdatasourceブロックの名前です
さらに、イントロスペクション中に型属性は、基盤となるネイティブ型が**デフォルトの型ではない**場合にのみスキーマに追加されます。例えば、PostgreSQLプロバイダーを使用している場合、基盤となるネイティブ型がtextであるStringフィールドには型属性は含まれません。
スカラー型とプロバイダーごとのネイティブデータベース型属性の完全なリストを参照してください。
利点とワークフロー
- Prisma Migrateがデータベースに作成する**正確なネイティブ型**を制御します - 例えば、
Stringは@db.VarChar(200)または@db.Char(50)にできます - イントロスペクト時に**リッチなスキーマ**を参照できます
型修飾子
フィールドの型は、次の2つの修飾子のいずれかを付加することで変更できます
注:型修飾子を組み合わせることは**できません** - オプションのリストはサポートされていません。
リスト
以下の例には、スカラーリストと関連モデルのリストが含まれています
- リレーショナルデータベース
- MongoDB
model Post {
id Int @id @default(autoincrement())
// Other fields
comments Comment[] // A list of comments
keywords String[] // A scalar list
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
// Other fields
comments Comment[] // A list of comments
keywords String[] // A scalar list
}
注:スカラーリストは、データベースコネクタがスカラーリストを、ネイティブまたはPrisma ORMレベルでサポートしている場合に**のみ**サポートされます。
オプションフィールドと必須フィールド
- リレーショナルデータベース
- MongoDB
model Comment {
id Int @id @default(autoincrement())
title String
content String?
}
model Tag {
name String @id
}
model Comment {
id String @id @default(auto()) @map("_id") @db.ObjectId
title String
content String?
}
model Tag {
name String @id @map("_id")
}
フィールドに?型修飾子を**付加しない**場合、そのフィールドはモデルのすべてのレコードで必須となります。これは2つのレベルに影響します
- データベース
- リレーショナルデータベース:必須フィールドは、基盤となるデータベースで
NOT NULL制約として表されます。 - MongoDB:MongoDBデータベースレベルでは、必須フィールドという概念はありません。
- リレーショナルデータベース:必須フィールドは、基盤となるデータベースで
- Prisma Client:Prisma Clientによって生成される、アプリケーションコード内のモデルを表すTypeScript型は、これらのフィールドを必須として定義し、常に実行時に値を持つことを保証します。
注:オプションフィールドのデフォルト値は
nullです。
サポートされていない型
リレーショナルデータベースをイントロスペクトすると、サポートされていないデータ型はUnsupportedとして追加されます。
location Unsupported("POLYGON")?
Unsupported型を使用すると、Prisma ORMでまだサポートされていないデータベース型に対して、Prismaスキーマでフィールドを定義できます。例えば、MySQLのPOLYGON型は現在Prisma ORMではサポートされていませんが、Unsupported("POLYGON")型を使用してPrismaスキーマに追加できるようになりました。
Unsupported型のフィールドは生成されたPrisma Client APIには表示されませんが、Prisma ORMの生データベースアクセス機能を使用してこれらのフィールドをクエリできます。
注:モデルに**必須の
Unsupportedフィールド**がある場合、生成されたクライアントにはそのモデルのcreateまたはupdateメソッドは含まれません。
注:MongoDBコネクタはすべてのスカラー型をサポートしているため、
Unsupported型をサポートも要求もしません。
属性の定義
属性はフィールドまたはモデルブロックの動作を変更します。以下の例には、3つのフィールド属性(@id、@default、および@unique)と1つのブロック属性(@@unique)が含まれています。
- リレーショナルデータベース
- MongoDB
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@unique([firstName, lastName])
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@unique([firstName, lastName])
}
一部の属性は引数を受け入れます - 例えば、@defaultはtrueまたはfalseを受け入れます。
isAdmin Boolean @default(false) // short form of @default(value: false)
フィールドとブロック属性の完全なリストを参照してください。
IDフィールドの定義
IDはモデルの個々のレコードを一意に識別します。モデルは1つのIDのみを持つことができます
- リレーショナルデータベースでは、IDは単一フィールドまたは複数のフィールドに基づいて定義できます。モデルに
@idまたは@@idがない場合、代わりに必須の@uniqueフィールドまたは@@uniqueブロックを定義する必要があります。 - MongoDBでは、IDは
@id属性と@map("_id")属性を定義する単一のフィールドでなければなりません。
リレーショナルデータベースでのIDの定義
リレーショナルデータベースでは、IDは@id属性を使用する単一フィールド、または@@id属性を使用する複数フィールドで定義できます。
単一フィールドID
以下の例では、User IDはid整数フィールドで表されます。
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
複合ID
以下の例では、User IDはfirstNameとlastNameフィールドの組み合わせで表されます。
model User {
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@id([firstName, lastName])
}
デフォルトでは、Prisma Clientクエリにおけるこのフィールドの名前はfirstName_lastNameになります。
@@id属性のnameフィールドを使用して、複合IDに独自の命名をすることもできます。
model User {
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@id(name: "fullName", fields: [firstName, lastName])
}
firstName_lastNameフィールドは、代わりにfullNameという名前になります。
複合IDの操作に関するドキュメントを参照し、Prisma Clientで複合IDを操作する方法を学んでください。
@uniqueフィールドをユニーク識別子として使用する
以下の例では、ユーザーは@uniqueフィールドによって一意に識別されます。emailフィールドがモデルの一意の識別子として機能するため(これは必須です)、強制的に必須となります。
model User {
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
リレーショナルデータベースにおける制約名
基盤となるデータベースで、オプションでカスタムプライマリキージェット制約名を定義できます。
MongoDBでのIDの定義
MongoDBコネクタには、リレーショナルデータベースとは異なるIDフィールドを定義するための特定のルールがあります。IDは@id属性を使用する単一フィールドで定義され、@map("_id")を含める必要があります。
以下の例では、User IDは、自動生成されたObjectIdを受け入れるid文字列フィールドで表されます。
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
以下の例では、User IDは、ObjectId以外のもの(例えば、一意のユーザー名)を受け入れるid文字列フィールドで表されます。
model User {
id String @id @map("_id")
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
MongoDBは@@idをサポートしていません
MongoDBは複合IDをサポートしていません。つまり、@@idブロックでモデルを識別することはできません。
デフォルト値の定義
@default属性を使用して、モデルのスカラーフィールドのデフォルト値を定義できます。
- リレーショナルデータベース
- MongoDB
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
title String
published Boolean @default(false)
data Json @default("{ \"hello\": \"world\" }")
author User @relation(fields: [authorId], references: [id])
authorId Int
categories Category[] @relation(references: [id])
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
categories Category[] @relation(references: [id])
}
@default属性は以下のいずれかです
- 基盤となるデータベースの
DEFAULT値を表す(リレーショナルデータベースのみ)か、 - Prisma ORMレベルの関数を使用します。例えば、
cuid()とuuid()は、すべてのコネクタに対してPrisma Clientのクエリエンジンによって提供されます。
デフォルト値は次のようになります
- フィールドの型に対応する静的値、例えば
5(Int)、Hello(String)、またはfalse(Boolean) - 静的値のリスト、例えば
[5, 6, 8](Int[]) や["Hello", "Goodbye"](String[]). これらは、サポートされているデータベース(PostgreSQL、CockroachDB、MongoDB)を使用している場合、Prisma ORMのバージョン4.0.0以降で利用可能です。 - 関数、例えば
now()またはuuid() - JSONデータ。JSONは
@default属性内で二重引用符で囲む必要があることに注意してください(例:@default("[]"))。JSONオブジェクトを提供したい場合は、二重引用符で囲み、内部の二重引用符はバックスラッシュでエスケープする必要があります(例:@default("{ \"hello\": \"world\" }"))。
関数に対するコネクタのサポートに関する情報については、属性関数リファレンスドキュメントを参照してください。
ユニークフィールドの定義
モデルにユニーク属性を追加することで、そのモデルの個々のレコードを一意に識別できるようになります。ユニーク属性は、@unique属性を使用して単一のフィールドに、または複数のフィールド(複合または結合ユニーク制約とも呼ばれます)に@@unique属性を使用して定義できます。
以下の例では、emailフィールドの値は一意である必要があります。
- リレーショナルデータベース
- MongoDB
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
email String @unique
name String?
}
以下の例では、authorIdとtitleの組み合わせは一意である必要があります。
- リレーショナルデータベース
- MongoDB
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
categories Category[] @relation(references: [id])
@@unique([authorId, title])
}
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
categories Category[] @relation(references: [id])
@@unique([authorId, title])
}
リレーショナルデータベースにおける制約名
基盤となるデータベースで、オプションでカスタムユニーク制約名を定義できます。
デフォルトでは、Prisma Clientクエリにおけるこのフィールドの名前はauthorId_titleになります。
@@unique属性のnameフィールドを使用して、複合ユニーク制約に独自の命名をすることもできます。
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
categories Category[] @relation(references: [id])
@@unique(name: "authorTitle", [authorId, title])
}
authorId_titleフィールドは、代わりにauthorTitleという名前になります。
複合ユニーク識別子の操作に関するドキュメントを参照し、Prisma Clientで複合ユニーク制約を操作する方法を学んでください。
複合型のユニーク制約
MongoDBプロバイダーをバージョン3.12.0以降で使用する場合、@@unique([compositeType.field])という構文を使用して複合型のフィールドにユニーク制約を定義できます。他のフィールドと同様に、複合型のフィールドは複数列ユニーク制約の一部として使用できます。
以下の例では、Userモデルのemailフィールドと、User.addressで使用されるAddress複合型のnumberフィールドに基づいて、複数列ユニーク制約を定義しています。
type Address {
street String
number Int
}
model User {
id Int @id
email String
address Address
@@unique([email, address.number])
}
ネストされた複合型が複数ある場合、この記法は連鎖させることができます。
type City {
name String
}
type Address {
number Int
city City
}
model User {
id Int @id
address Address[]
@@unique([address.city.name])
}
インデックスの定義
モデルの1つまたは複数のフィールドに、モデル上の@@indexを通じてインデックスを定義できます。以下の例では、titleフィールドとcontentフィールドに基づいた複数列インデックスを定義しています。
model Post {
id Int @id @default(autoincrement())
title String
content String?
@@index([title, content])
}
リレーショナルデータベースにおけるインデックス名
基盤となるデータベースで、オプションでカスタムインデックス名を定義できます。
複合型のインデックスの定義
MongoDBプロバイダーをバージョン3.12.0以降で使用する場合、@@index([compositeType.field])という構文を使用して複合型のフィールドにインデックスを定義できます。他のフィールドと同様に、複合型のフィールドは複数列インデックスの一部として使用できます。
以下の例では、UserモデルのemailフィールドとAddress複合型のnumberフィールドに基づいて、複数列インデックスを定義しています。
type Address {
street String
number Int
}
model User {
id Int @id
email String
address Address
@@index([email, address.number])
}
ネストされた複合型が複数ある場合、この記法は連鎖させることができます。
type City {
name String
}
type Address {
number Int
city City
}
model User {
id Int @id
address Address[]
@@index([address.city.name])
}
Enumの定義
Enumがデータベースコネクタでサポートされている場合、ネイティブまたはPrisma ORMレベルで、データモデルにenumを定義できます。
EnumはPrismaスキーマデータモデルではスカラー型と見なされます。そのため、デフォルトでPrisma Clientクエリの戻り値として含まれます。
Enumはenumブロックで定義されます。例えば、UserはRoleを持ちます。
- リレーショナルデータベース
- MongoDB
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
role Role @default(USER)
}
enum Role {
USER
ADMIN
}
model User {
id String @id @default(auto()) @map("_id") @db.ObjectId
email String @unique
name String?
role Role @default(USER)
}
enum Role {
USER
ADMIN
}
複合型の定義
複合型はバージョン3.10.0でmongodbプレビュー機能フラグの下で追加され、バージョン3.12.0以降では一般利用可能(General Availability)となっています。
複合型は現在、MongoDBでのみ利用可能です。
複合型(MongoDBでは埋め込みドキュメントとして知られています)は、新しいオブジェクト型を定義できるようにすることで、他のレコード内にレコードを埋め込む機能をサポートします。複合型は、モデルと同様の方法で構造化され、型付けされます。
複合型を定義するには、typeブロックを使用します。例として、以下のスキーマをご覧ください。
model Product {
id String @id @default(auto()) @map("_id") @db.ObjectId
name String
photos Photo[]
}
type Photo {
height Int
width Int
url String
}
この場合、Productモデルはphotosに格納されたPhoto複合型のリストを持っています。
複合型を使用する際の考慮事項
複合型は限られた属性セットのみをサポートします。以下の属性がサポートされています。
@default@map@db.ObjectIdなどのネイティブ型
以下の属性は複合型内でサポートされていません
@unique@id@relation@ignore@updatedAt
ただし、ユニーク制約は、複合型を使用するモデルのレベルで@@unique属性を使用することで定義できます。詳細については、「複合型のユニーク制約」を参照してください。
インデックスは、複合型を使用するモデルのレベルで@@index属性を使用することで定義できます。詳細については、「複合型のインデックスの定義」を参照してください。
関数の使用
Prismaスキーマは多数の関数をサポートしています。これらはモデルのフィールドのデフォルト値を指定するために使用できます。
例えば、createdAtのデフォルト値はnow()です。
- リレーショナルデータベース
- MongoDB
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
}
model Post {
id String @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
}
cuid()とuuid()はPrisma ORMによって実装されているため、基盤となるデータベーススキーマでは「可視」ではありません。イントロスペクションを使用する際に、Prismaスキーマを手動で変更し、Prisma Clientを生成することで、引き続きこれらを使用できます。その場合、値はPrisma Clientのクエリエンジンによって生成されます。
autoincrement()、now()、およびdbgenerated(...)のサポートはデータベースによって異なります。
リレーショナルデータベースコネクタは、autoincrement()、dbgenerated(...)、およびnow()をデータベースレベルで実装します。MongoDBコネクタはautoincrement()またはdbgenerated(...)をサポートせず、now()はPrisma ORMレベルで実装されます。auto()関数はObjectIdを生成するために使用されます。
リレーション
モデル間の関係に関する詳細な例と情報については、リレーションのドキュメントを参照してください。
Prisma Clientにおけるモデル
クエリ(CRUD)
データモデル定義内のすべてのモデルは、生成されたPrisma Client APIにおいて多数のCRUDクエリを生み出します
findMany()findFirst()findFirstOrThrow()findUnique()findUniqueOrThrow()create()update()upsert()delete()createMany()createManyAndReturn()updateMany()updateManyAndReturn()deleteMany()
これらの操作は、Prisma Clientインスタンス上の生成されたプロパティを介してアクセスできます。デフォルトでは、プロパティの名前はモデル名の小文字形式です。例えば、Userモデルの場合はuser、Postモデルの場合はpostです。
以下は、Prisma Client APIのuserプロパティの使用例です。
const newUser = await prisma.user.create({
data: {
name: 'Alice',
},
})
const allUsers = await prisma.user.findMany()
型定義
Prisma Clientは、モデル構造を反映する型定義も生成します。これらは、生成された@prisma/clientノードモジュールの一部です。
TypeScriptを使用する場合、これらの型定義により、すべてのデータベースクエリが完全に型安全になり、コンパイル時に検証されます(selectやincludeを使用する部分的なクエリでも同様です)。
プレーンなJavaScriptを使用する場合でも、型定義は@prisma/clientノードモジュールに含まれており、エディタでのIntelliSense/自動補完などの機能が有効になります。
注:実際の型は
.prisma/clientフォルダに保存されています。@prisma/client/index.d.tsはこのフォルダの内容をエクスポートします。
例えば、上記のUserモデルの型定義は次のようになります。
export type User = {
id: number
email: string
name: string | null
role: string
}
リレーションフィールドであるpostsとprofileは、デフォルトでは型定義に含まれないことに注意してください。ただし、User型のバリエーションが必要な場合は、Prisma Clientが生成するヘルパー型(この場合、これらのヘルパー型はUserGetIncludePayloadおよびUserGetSelectPayloadと呼ばれます)を使用して定義することができます。
制限事項
レコードは一意に識別可能である必要があります
Prisma ORMは現在、少なくとも1つのユニークなフィールド、またはフィールドの組み合わせを持つモデルのみをサポートしています。実際には、これはすべてのPrismaモデルが以下の属性の少なくとも1つを持つ必要があることを意味します。
- 単一フィールドまたは複数フィールドの主キー制約のための
@idまたは@@id(モデルごとに最大1つ) - 単一フィールドまたは複数フィールドのユニーク制約のための
@uniqueまたは@@unique