Prisma Postgres は、市場で最も革新的なPostgreSQLデータベースです。この記事では、超高速クエリ、グローバルキャッシュ、コネクションプーリングなどを可能にするその技術スタックについて詳しく掘り下げます。

要点:Prisma Postgresとは?
もしご存知なければ:Prisma Postgresはユニカーネル上に構築された初のデータベースです。見逃した方のために、100秒の簡単な要約です
次世代インフラストラクチャ上に構築
Prisma Postgresは単なるAWSラッパーではありません!そのアーキテクチャは、ユニカーネル、Unikraft Cloud、Cloudflare Workersのような次世代インフラストラクチャに基づき、第一原理から慎重に設計されています。
これらの技術の組み合わせは、独自の利点と強力な機能セットを提供します。
コールドスタートなし、グローバルキャッシュ、コネクションプーリングなど
開発者がPrisma Postgresをサーバーレスデータベースとして使用する際に得られるものは以下の通りです
- コールドスタートゼロ:遅延なくデータベースに即座にアクセス。
- 充実した無料枠:月間10万オペレーション、1GiBストレージ、10データベース。
- グローバルキャッシュ層:クエリ応答はエッジで簡単にキャッシュされます。
- 組み込みのコネクションプール:TCP接続を気にすることなくアプリをスケーリング。
- パフォーマンスのヒント:クエリを高速化するためのAIによる推奨事項。
- シンプルな従量課金制:オペレーションとストレージに基づいた予測可能なコスト。
Prisma Postgresを試す
Prisma Postgresクエリのライフサイクル
簡単な要約を終えたところで、Prisma Postgresがこれらの利点を可能にするために使用する技術スタックを詳しく見ていきましょう。ネタバレ注意:Prisma Postgresクエリのライフサイクルに関わる全コンポーネントの概要はこちらです
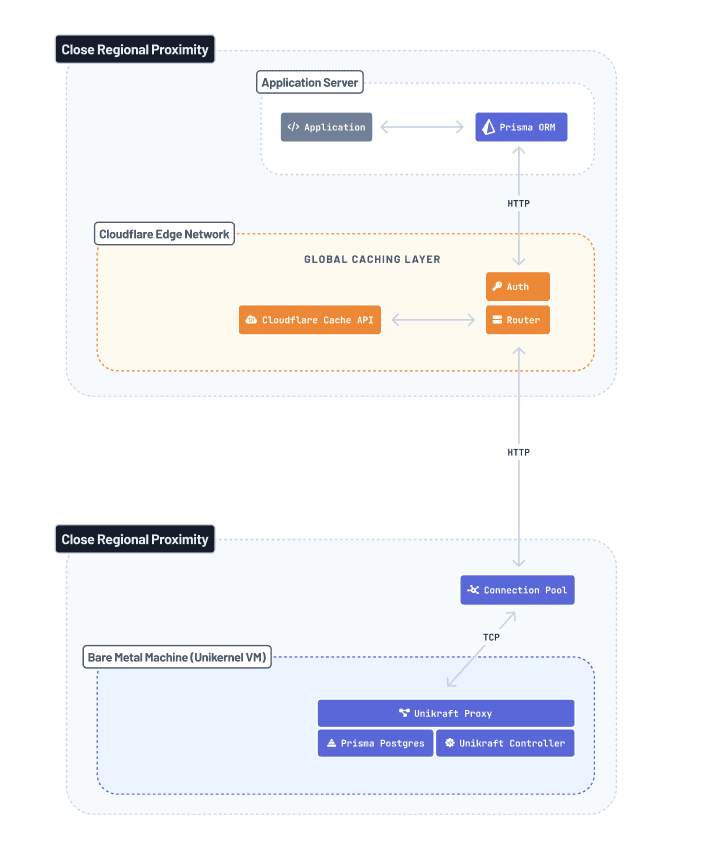
次のセクションでは、各ステージを詳しく見て、内部で何が起こっているかを説明します。
ステージ1:すべてはPrisma ORMから始まる
Prisma ORM は、Prisma Postgresクエリの旅が自然に始まる場所です。
Prisma Postgresではアプリケーションサーバーにクエリエンジンは不要
これまでPrisma ORMを使用されたことがある方は、Rustで実装され、アプリケーションサーバー上でバイナリとして動作する*クエリエンジン*を使用していることをご存知かもしれません。
この文脈では、クエリエンジンがRustで書かれていることに言及していますが、現在TypeScriptで書き直されています。詳細はこちらをご覧ください。
クエリエンジンの主な役割は以下の通りです
- 高レベルORMクエリ(JS/TSで記述)に基づいて効率的なSQLクエリを生成する
- データベースコネクションプールを管理する
しかし、Prisma ORMをPrisma Postgresと組み合わせて使用する際の優れた点は、アプリケーションサーバー上でクエリエンジンを実行する必要がないことです。代わりに、クエリエンジン*なし*の超軽量版Prisma ORMを使用します。SQLクエリの生成とTCP接続の管理という重い処理は、スタックのさらに下、Prisma Postgresの上に位置するコネクションプールに押し込まれます。
Prisma Postgresインフラストラクチャ上でコネクションプールをホストするこのアプローチには、大きな利点があります。アプリケーション開発者はコネクションプールの管理から解放され、データ要件とクエリに集中できます。また、サーバーレスやエッジ関数のような短命な環境では、コネクションプールを繰り返し再作成することが大きなパフォーマンスオーバーヘッドを引き起こすため、特に有用です。
キャッシュ戦略を伴うPrisma ORMクエリの定義
この記事の目的のために、以下のPrisma ORMクエリを使用してみましょう
このクエリは、データベースから公開されたすべての投稿を取得し、さらにPrisma Postgresキャッシュに関連する2つのパラメータを指定します
- Time-To-Live (
ttl):キャッシュされたデータが*新鮮*であるとみなされる期間を決定します。TTL値を設定すると、Prisma Postgresはその期間、データベースにクエリを発行することなくキャッシュされたデータを提供します。 - Stale-While-Revalidate (
swr):Prisma Postgresがバックグラウンドで新しいデータをフェッチしながら、*古い*キャッシュデータを提供することを許可します。SWR値を設定すると、Prisma PostgresはTTLが過ぎた後もその期間キャッシュデータを供給し続け、同時にデータベースから新しいデータを取得してキャッシュを更新します。
この例では、データは30秒間(TTL)新鮮であるとみなされます。その後、次の60秒間(SWR)は、Prisma Postgresのキャッシュが古いデータを提供しつつ、バックグラウンドで新しいデータをフェッチします。
Prisma Postgresは、アプリケーションに近いエッジロケーションからキャッシュデータを提供します。アプリケーションを複数の場所にデプロイする場合、このグローバルキャッシュはアプリのパフォーマンスを劇的に向上させることができます!
HTTP経由でのクエリ実行
では、上記のクエリがアプリケーションで実行されると、次に何が起こるのでしょうか?クエリエンジンがスタックの下層に押し込まれているため、この段階で起こることは、Prisma Postgresのインフラストラクチャの最初の認証およびルーティングレイヤーへのHTTPリクエストだけです。このHTTPリクエストには、クエリの軽量なJSONベースの表現が含まれています。その内容は以下の通りです
`selection`引数は、データベースから取得するフィールドを指定することに注意してください。今回のクエリでは`select`または`include`オプションを使用していないため、その値は単純に`"$scalars": true`となっており、これは対象モデルのすべてのスカラーフィールドがデータベースから返されることを意味します。
次のステップは、Prisma Postgresの認証およびキャッシュ層によるリクエストの評価です。
ステージ2:リクエストの認証
クエリ結果がキャッシュから提供可能かどうかをチェックするためにキャッシュにアクセスする前に、クエリは認証される必要があります。Prisma PostgresのURLには常にユーザー認証情報をエンコードするapiKey引数が含まれています
認証層はCloudflare Workersを使用して実装されており、したがってクエリの発信元と物理的に近い場所にあります。これはapiKey値を使用してユーザーを識別し、アクセス権限を検証し、リクエストを次のステージにルーティングします。
ステージ3:キャッシュするか否か
認証後、HTTPリクエストはPrisma Postgresインフラストラクチャの次の層に到達します。これもCloudflare Workersを介して実装されています
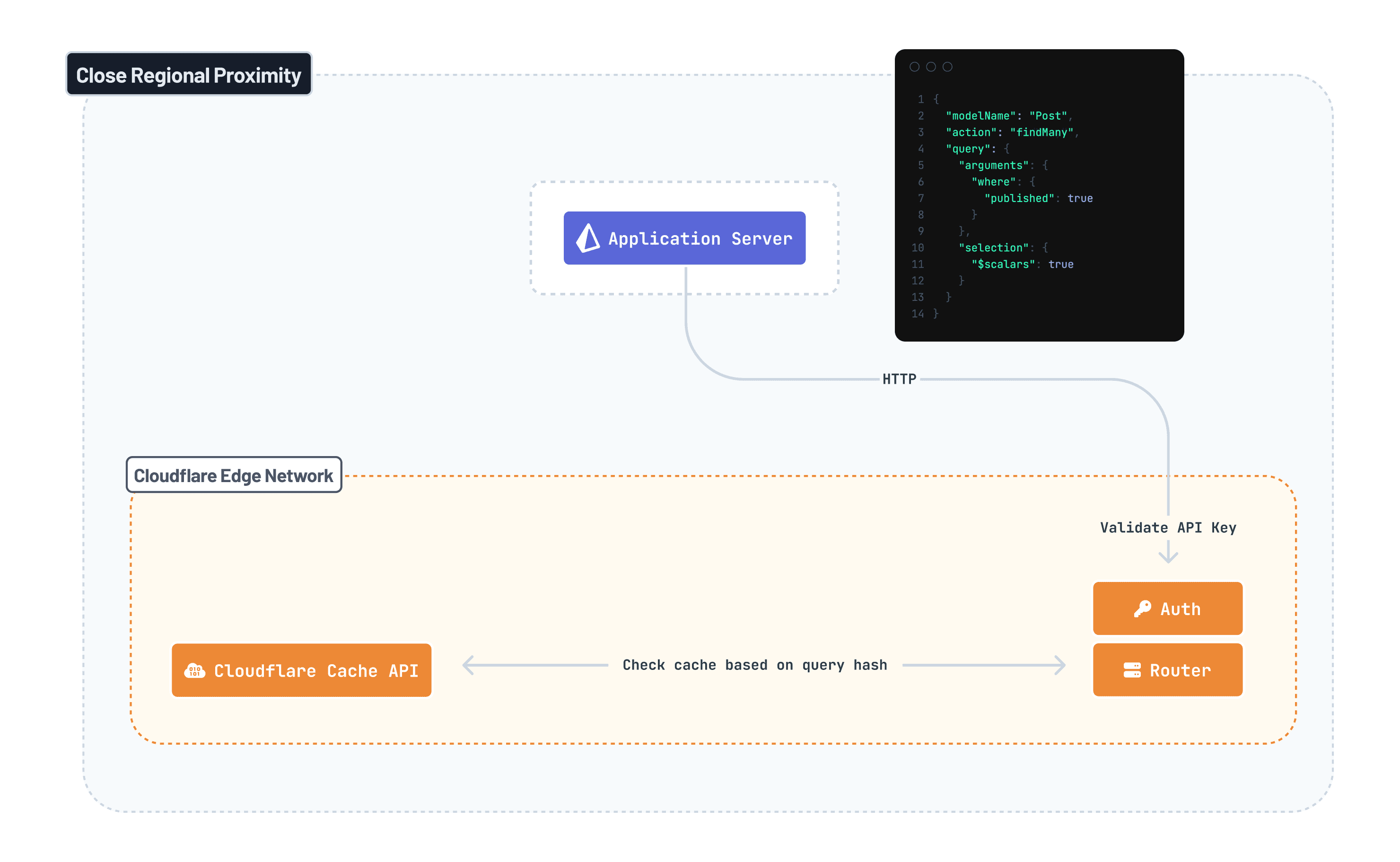
このルーティング層の主な目的は、Prisma Postgresキャッシュを有効にする必要があるかどうかを判断することです
- クエリに
swrおよび/またはttlオプションが設定されている場合、クエリはPrisma Postgresキャッシュへのパスに入ります。 - これらのキャッシュオプションのいずれも持たない場合、クエリは直接次のステージに進みます。
それでは、Prisma Postgresのキャッシュ層を経由するパスを見ていきましょう。
Cloudflare Workers上に構築されているため、Prisma Postgresキャッシュは公式のCloudflare Cache APIを利用しています。
キャッシュキーとしては、Prisma ORMクエリ*全体*(上記のpublished: trueのようなクエリパラメータの値を含む)に基づいて計算されたハッシュを使用します。このアプローチはキャッシュミスを起こしやすい傾向がありますが、この正確なクエリがデータベースに送信され、その結果が以前にキャッシュされたことが100%確実である場合にのみ、キャッシュからデータを返します。
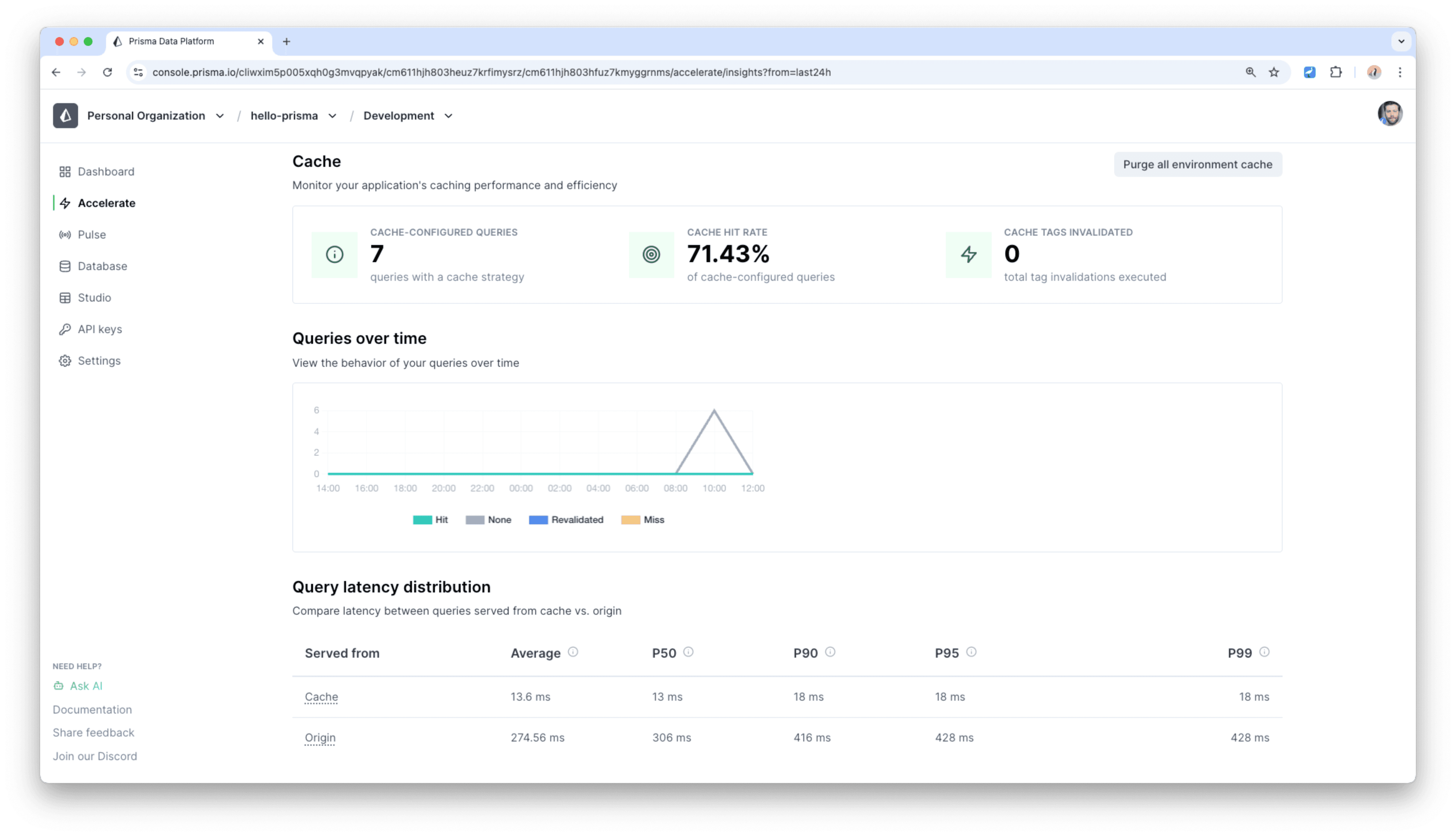
キャッシュ動作の統計は、Prisma Postgresダッシュボードで確認できます
それでは、先ほどのクエリがPrisma Postgresスタックをさらに下に進み、キャッシュによって処理されなかったと仮定しましょう。次に何が起こるのでしょうか?
ステージ4:コネクションプールへの到達
クエリ結果がキャッシュされていなかった場合、先ほどのHTTPリクエストは次の目的地であるPrisma Postgresのコネクションプール(データベースインスタンスと物理的に近い場所で実行されているVMにデプロイされている)に転送されます。
コネクションプーリングがなぜ重要なのかについては、最近の記事「コネクションプーリングでブラックフライデーを救う」で詳しく解説しています。
なお、これはリクエストがCloudflareリージョンの地域境界を越えるため、実際に長距離を移動する最初(そして唯一)の機会であることに注意してください。
これらのVMは、アプリケーションサーバーから移動された(ステージ1で説明した)クエリエンジンをホストしています。したがって、この段階でPrisma Postgresのコネクションプールは、実際にクエリを実行するためのアイドル状態の接続を見つけるだけでなく、Prisma Postgresに送信されるSQLステートメントも生成します。これは、昔ながらのTCP接続を介してデータベースに行われます。
ステージ5:ユニカーネルデータベースへの到達
Prisma Postgresは、我々独自のベアメタルサーバー上で超軽量のmicroVMとして動作する*ユニカーネル*(「超専門化されたオペレーティングシステム」と考えてください)に基づいています。
そのアーキテクチャの詳細、Unikraftとの共同作業、そしてPrisma Postgresのパフォーマンス上の利点を可能にするミリ秒単位のクラウドスタックについて学ぶには、早期アクセス発表をご覧ください。
Prisma Postgresインスタンスの超高速起動時間を可能にするUnikraft Cloudの コアコンポーネント の概要です

そして、これらのコンポーネントがどのように連携するかを説明します
- カスタムコントローラーとプロキシ:クラス最高のリアクティブなミリ秒単位のセマンティクスとスケーラビリティを提供するカスタムプラットフォームコントローラーです。ネットワーク処理を高速化するため、Unikraft Cloudはこのコントローラーをカスタムプロキシと結合しており、負荷分散を処理し、受信リクエストに非常に迅速に反応することができます。このプロキシは、Prisma PostgresのコネクションプールへのTCP接続が管理される場所です。
- Firecracker とユニカーネルに基づく高速仮想マシンモニター(VMM):Unikraft Cloudのユニカーネルは、Prisma Postgresのみを含む軽量なイメージを使用します。それ以外は何もありません。Firecracker VMMの修正版と組み合わせることで、これらのPrisma Postgresイメージは超高速で起動します。
- スナップショット:Unikraft Cloudは、Prisma Postgresインスタンスをゼロにスケールする前にメモリのスナップショットを取得します。これらを起動する際、スナップショットから再開するため、VMはすでに「ウォームアップ」しており、アクティブなTCP接続さえも含まれています!
この非常に効率的なスタックのおかげで、データベースインスタンスは実際に使用した場合にのみコストが発生します。これにより、私たちは寛大な無料枠を提供でき、好きなだけ無料でPrisma Postgresインスタンスを起動できます(これは、通常、複数のデータベースインスタンスを作成すると固定の月額料金が発生する他のプロバイダーとは対照的です)。
クエリの話に戻りましょう。クエリの初期JSON表現が効率的なSQLステートメントに変換された後、クエリは最終的にTCPを介してデータベース層に到達します。PostgreSQLインスタンスは、Unikraftのミリ秒単位のクラウドスタックを使用して、コネクションプールに近接した独自のベアメタルサーバー上にデプロイされます。
ここでの最初の停止点はUnikraftプロキシで、コネクションプールへのTCP接続の維持を担当しています。
プロキシは、実際のPrisma Postgresインスタンスの管理を担当するUnikraftコントローラーと通信します。この時点で、2つの状態が考えられます
- ターゲットのPrisma Postgresインスタンスがすでに稼働している場合、プロキシは直接クエリを転送し続けます。
- またはPrisma Postgresインスタンスが現在「一時停止」している場合、プロキシはUnikraftコントローラーに連絡し、UnikraftコントローラーがターゲットのPrisma Postgresインスタンスを識別し、「起動」させ、現在のインスタンスステータスをプロキシに通知します。
ここでの「一時停止」と「起動」という用語に戸惑わないでください。超高速VMスナップショット(*メモリ内*で発生)とユニカーネルの軽量性のおかげで、各インスタンスは数ミリ秒の間に再び起動できます(これがPrisma Postgresインスタンスがコールドスタートに悩まされない秘密です)。
Prisma Postgresアーキテクチャの今後の展望
現在の技術スタックとそれが開発者に提供するメリットについて、すでに多くの興奮が見られますが、私たちはここで止まるつもりはありません!
Prisma Postgresの将来のイテレーションで可能と思われる追加の最適化がいくつかあります。最も注目すべきは、次の点です。Prisma Postgresインスタンスが実行されている*同じマシン*にコネクションプールを移動する予定です
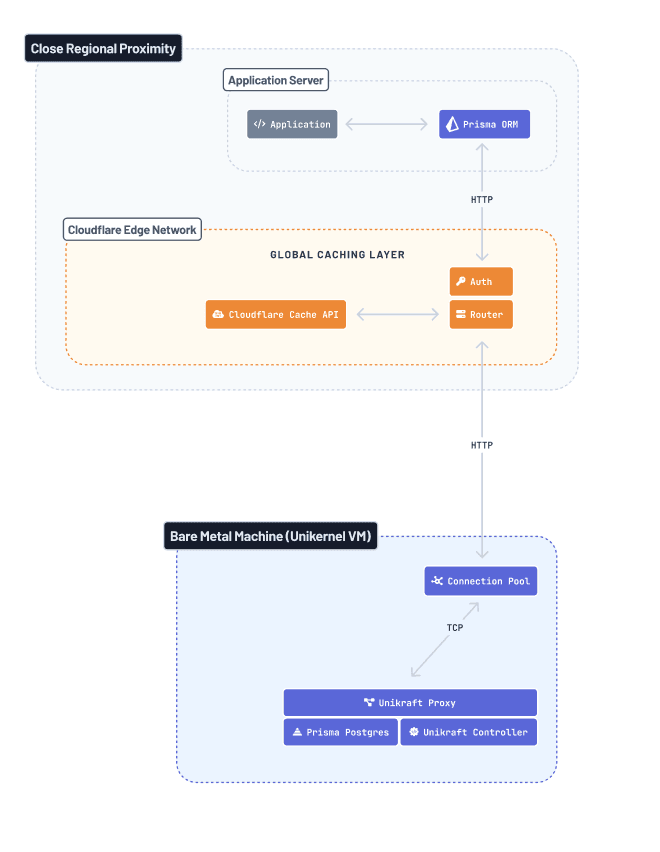
TCP接続は、接続が確立されるたびに行われるスリーウェイハンドシェイクのため、スタック全体で最もコストのかかる部分です。このTCP接続を、同じマシン上の2つのプロセス間で発生する単なるローカルなものに減らすことで、コネクションプールとデータベースインスタンス間の物理的距離によって引き起こされるレイテンシは完全に無視できるようになります。
これは、AWS(または他のクラウドプロバイダー)のインフラストラクチャに基づいている他のプロバイダーと比較したPrisma Postgresの核となる利点です。クラウドプロバイダーを使用する場合、コネクションプールとデータベースインスタンスが同じホスト上で実行されているという保証はなく、常にネットワークホップが発生します。
結論
この記事では、Prisma Postgresとその上に構築されている次世代の技術スタックの内部を詳しく見てきました。
すでにPrisma ORMを使用している場合は、既存のデータベースからデータをインポートしてPrisma Postgresを試してみてください。そうでない場合は、ターミナルでこのコマンドを実行して、Prisma Postgresを一から試してみてください
次回の投稿をお見逃しなく!
Prismaニュースレターに登録する