最新のサーバーレスおよびエッジランタイムは、高速でスケーラブルなアプリケーションのデプロイをかつてないほど容易にしました。しかし、アプリケーションが分散化するにつれて、パフォーマンスの問題はコードからインフラストラクチャへと移行することがよくあります。
この記事では、グローバルに分散されたアプリケーションに忍び込む一般的なバックエンドのボトルネック、すなわち、長いデータベースの往復、接続の頻繁な開閉(チャーン)、コールドスタート、非効率なクエリについて探ります。また、プーリング、キャッシング、リージョン対応デプロイ、よりスマートなモニタリングといった実践的な解決策についても詳しく説明し、ユーザーがどこにいてもアプリケーションの速度を維持できるようにします。

エッジとサーバーレスの本当の意味
さらに深く掘り下げる前に、まずその領域を簡単に定義しておきましょう。
サーバーレスとは、関数を記述してデプロイすれば、クラウドプロバイダーがオンデマンドでそれを実行することを意味します。インフラストラクチャについて考える必要はありません。自動的にスケールアップおよびスケールダウンします。
エッジとは、これらの関数がユーザーの近くで実行されることを意味します。たとえば、日本のユーザー向けには東京で、ドイツのユーザー向けにはフランクフルトでコードが実行されることがあります。これにより物理的な距離が短縮され、レイテンシーが削減されます。
これはフロントエンドの応答性と軽量なAPIには素晴らしいことですが、舞台裏では新たな課題を導入します。
ステートレス関数が事態を複雑にする理由
その課題の一つは、サーバーレスおよびエッジ関数がステートレスであることです。それらはリクエスト間で状態を保持しません。そのため、リクエストが来るたびに新しいインスタンスが起動され、データベースへの永続的な接続がない場合があります。
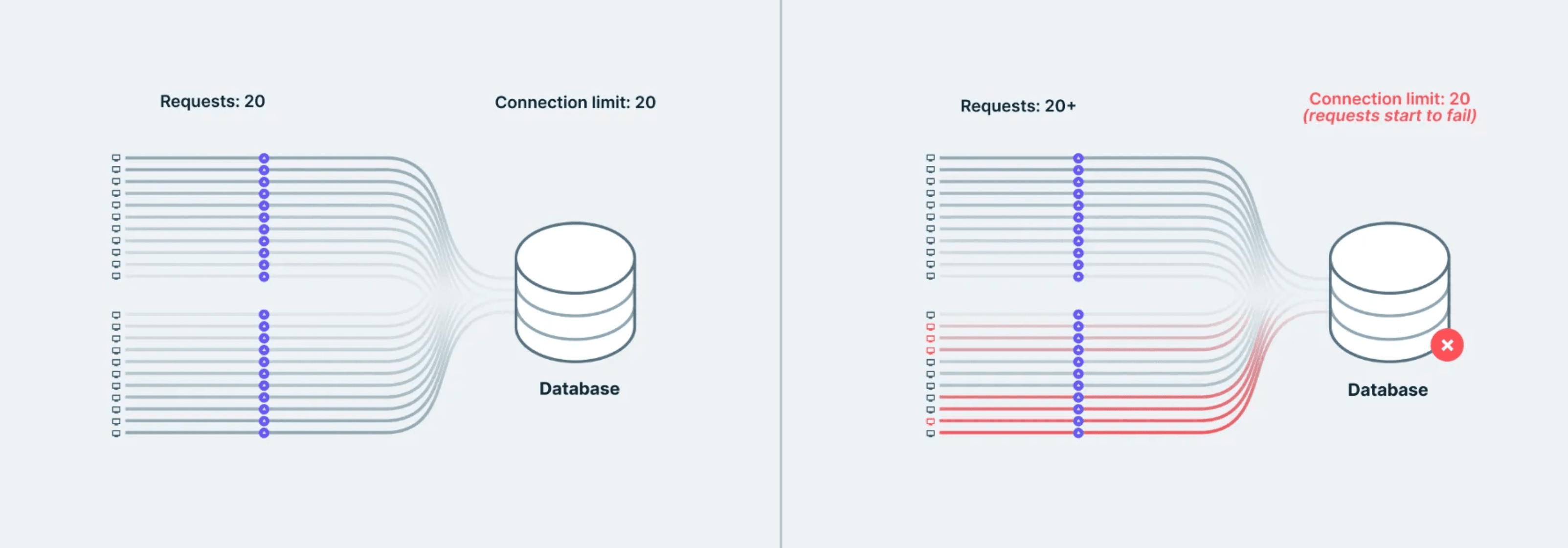
これは、コネクションチャーン(接続の頻繁な開閉)として知られる問題につながります。何百もの新しい接続が急速に開閉される現象です。
もし1000人のユーザーが同時にあなたの関数にアクセスした場合、それは短期間に1000個のデータベース接続が発生することを意味します。ほとんどのデータベースはそれに対応するように構築されていません。接続制限に達し、DBがスロットリングを開始し、すべてが遅くなります。
コールドスタートはこの問題をさらに悪化させます。関数が最近使用されていない場合、ランタイムが起動して新しい接続を確立する間、最初のリクエストは遅くなります。
コネクションプーリングを使用する
解決策は?コネクションプーリングです。
コネクションプーリングにより、複数の関数呼び出しが少数の永続的な接続セットを共有できます。これはデータベースの前にキューとして機能します。各関数が新しい接続を開く代わりに、プールから接続を取得します。
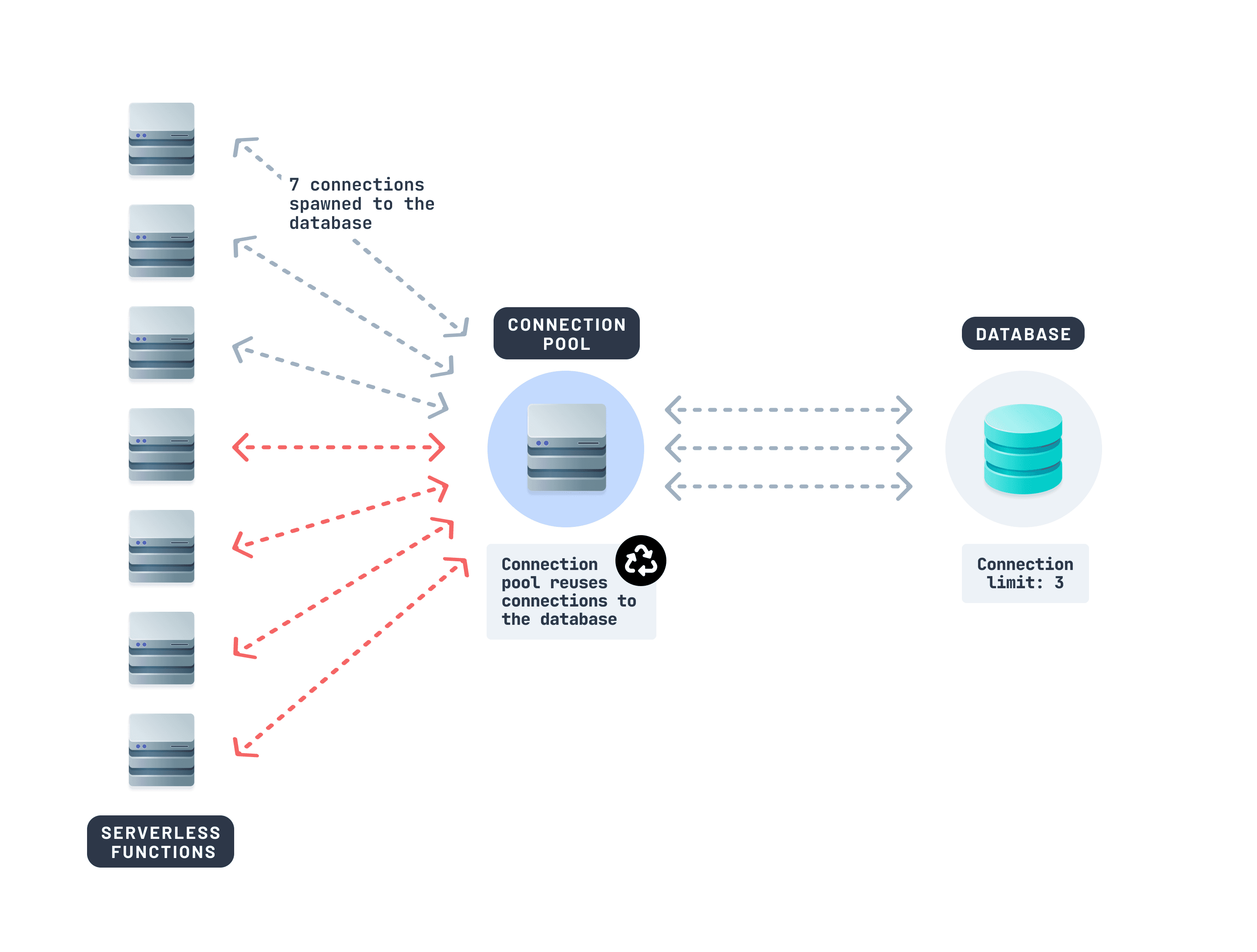
Prisma Postgresのようなデータベースを使用している場合、コネクションプーリングは舞台裏で処理されます。関数間でクエリが自動的にプーリングされ、最適化されます。PgBouncerやSupabaseのSupavisorのような他のツールも役立ちます。
データベースにコネクションプーラーを使用するだけで、高トラフィックのエッジ環境でのパフォーマンスを安定させることができます。
ここまでで、過剰な接続を管理する方法については説明しました。しかし、エッジパフォーマンスの低下の背後には、もう一つの隠れた犯人がいます。
エッジアプリが遅いのではなく、データベースへの往復が遅いのです
エッジ関数を東京にデプロイしたと想像してください。バージニア州のデータベースを呼び出すまでは、超高速で動作します。突然、応答時間が500ミリ秒も跳ね上がりました。
これはあなたのコードのせいではありません。地理的な問題です。
エッジランタイムは高速ですが、関数が海を越えてデータベースにクエリを送信しなければならない場合、各リクエストには数百ミリ秒の往復レイテンシーが追加されます。これが複数のクエリにわたると、ユーザーエクスペリエンスが低下します。
その解決策を探ってみましょう。
リアルタイムである必要のないデータをキャッシュする
不要なデータベース呼び出しを減らす最も簡単な方法の1つは、頻繁に変化しないデータをキャッシュすることです。
商品リスト、サイト設定、フィーチャーフラグなどを考えてみてください。これらの値は毎回新しくフェッチする必要はありません。
データベースクエリは以下を使用してキャッシュできます
- 適切な
Cache-Controlヘッダーを使用したCDNレベルのキャッシュ - エッジキーバリューデータベース(Vercel KV、Cloudflare Workers KVなど)
- ウォームなサーバーレス関数内のインメモリキャッシュ
- Prisma Postgresのような組み込みキャッシュを持つデータベースプロバイダーを使用する
キャッシングはデータベースの負荷を軽減し、繰り返されるリクエストの往復時間を大幅に短縮します。
関数とデータベースをコロケーションする
APIを高速化するもう一つの方法は、コードとデータベースを同じリージョンで実行することです。
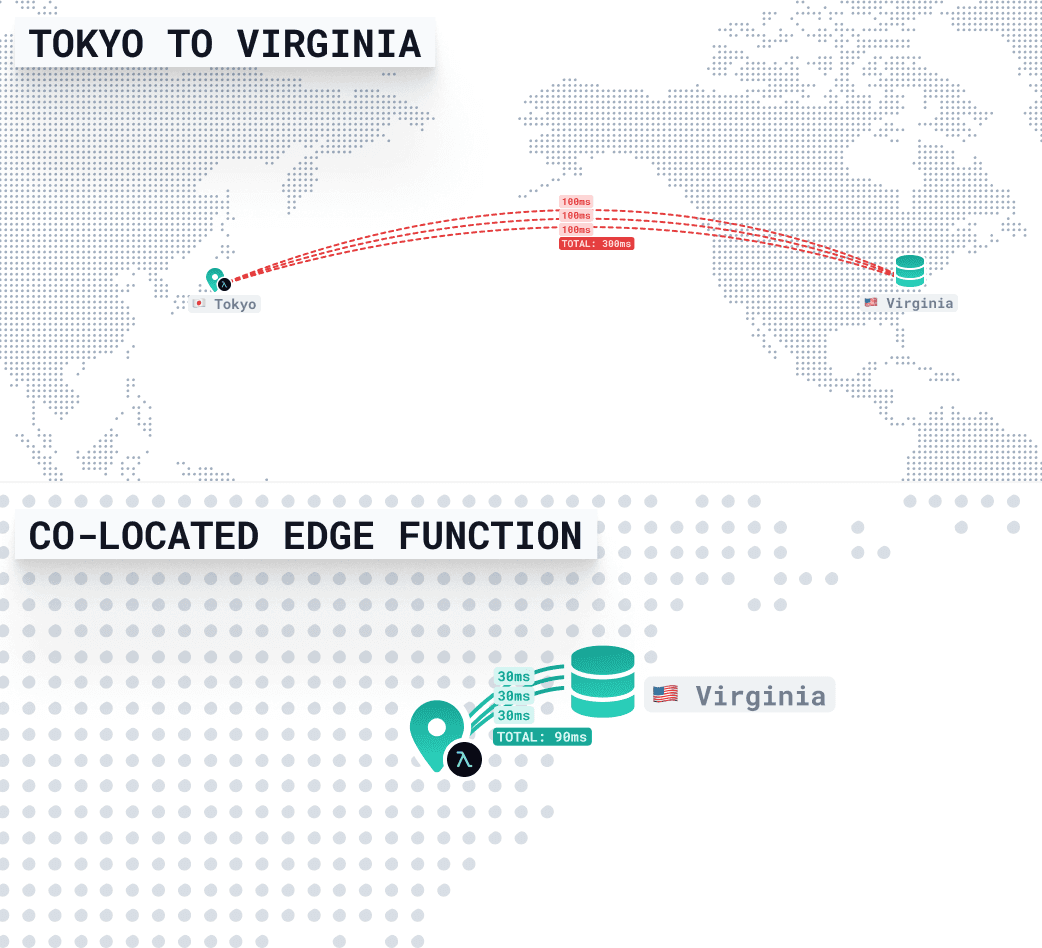
データベースがus-east-1(バージニア州)でホストされているとします。しかし、エッジ関数は東京から呼び出されます。関数がユーザーの近く(例:ap-northeast-1)で実行されていても、データベースが太平洋を越えて米国にある場合、すべてのクエリは長距離ネットワーク往復を複数回行う必要があります。
そこでレイテンシーが急速に蓄積される可能性があります。
関数は次のようになります
関数がユーザーの近く(東京)にありながら、データベースから遠い(バージニア州)場合、各データベースクエリは時間を要します。太平洋横断のネットワークレイテンシー、TLSハンドシェイク、DNS解決のため、1回の往復あたり約300msかかります。
このハンドラは、互いに依存する3つのクエリを順次実行します
- 3クエリ × 300ms = 合計レイテンシー約900ms
したがって、関数が実際の作業を行う前でさえ、データの待機に約1秒が費やされます。
それでは、コロケーションしましょう
データベースと同じリージョン(バージニア州)で関数を実行することで、これらのクエリは海を渡る必要がなくなります。それらはローカルに留まり、多くの場合、それぞれ10〜30msで完了します。
これは、東京からのリクエストであっても、全体の応答が90ms未満で返ってくることを意味します。ユーザーは距離に関連する多少のレイテンシーを待つことになりますが、バックエンドは高速かつ一貫性を保ちます。
リージョンピニングによりこれが可能に
Vercel、AWS Lambdaなどのプラットフォームでは、関数を特定のリージョンにピン留めすることができます。この場合、us-east-1です。
Vercelでのエッジデプロイの場合、region設定を使用することで、リージョンをピン留めできます
この設定が理想的なのは、以下の場合です。
- 複数のクエリを連続して実行する場合
- 複雑なクライアントサイドキャッシングの記述を避けたい場合
- 安定した低レイテンシーAPIを重視する場合
バックエンドを世界中に分散させるのではなく、コンピュートをデータとコロケーションすることで、たった1行の設定で何百ミリ秒ものオーバーヘッドを回避できます。
マルチリージョンデータベースを検討すべき場合
ほとんどのユーザーがデータの読み取りを行い、そのユーザーが世界中に分散している場合、マルチリージョンデータベースが役立ちます。
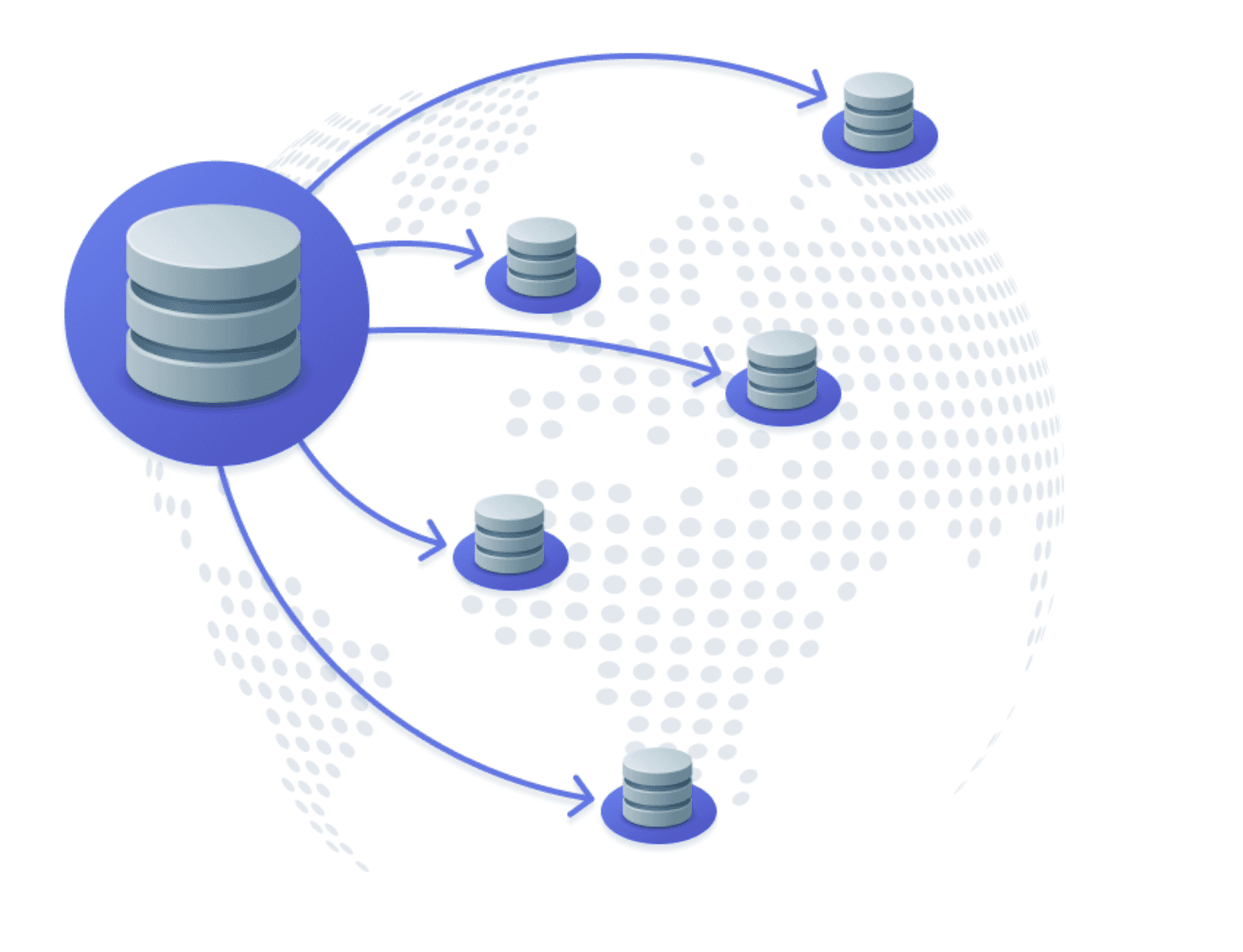
これにより、データが複数のリージョンに複製され、ヨーロッパ、アジア、オーストラリアのユーザーは最寄りのレプリカから読み取ります。これによりレイテンシーが改善され、単一のデータベースノードへの負荷が軽減されます。
AWSのようなクラウドプロバイダーは、DynamoDB Global TablesやAurora Globalといったマルチリージョン機能を提供していますが、CockroachDBのような専用データベースも、パフォーマンス向上のためにデータをリージョン間で簡単に複製できます。
分散データベースは以下の場合に優れた選択肢となります。
- 読み込みが書き込みを大幅に上回る場合
- わずかな陳腐化(結果整合性)が許容される場合
- グローバルな往復を減らしたい場合
ただし、以下の場合は控えてください。
- アプリに厳密な整合性が必要な場合(例:金融取引)
- 多くのリージョンで頻繁に書き込みが発生する場合
- バージョン競合を正確に制御する必要がある場合
クエリに目を光らせる
キャッシュを使用し、コロケーションされている場合でも、悪いクエリは依然としてパフォーマンスのボトルネックになる可能性があります。
パーセンタイルレイテンシーを追跡するために、早い段階でモニタリングを設定しましょう。
- p50 = 中央値のクエリ時間
- p75 = 通常は軽い負荷時でも遅いクエリ
- p99 = 最悪のケースのクエリ、パフォーマンス問題が隠れていることが多い場所
例えば、p50が30msというのは素晴らしいです。しかし、p99が700msだと、一部のユーザーは未だに不快な遅延に直面することになります。
パフォーマンスのボトルネックを特定する際には、以下も確認してください。
- N+1クエリパターン
- フィルタリングされたフィールドにインデックスが欠落している
- ネストされたデータの過剰なフェッチ
わずか数個の重いクエリを改善するだけで、全体のレイテンシーを半分にすることができます。Prisma Optimizeのようなツールは、エッジおよびサーバーレス関数全体で最も遅いクエリを特定し、根本原因を突き止め、実行可能な修正案を提案することで、これを容易にします。

簡単なまとめ
問題とその解決策を簡単に見ていきましょう。
最後に
エッジへのデプロイは簡単です。しかし、特にグローバルに、アプリケーションを高速に感じさせるには、もう少し検討が必要です。
良いニュースは?スタックを再構築する必要はありません。キャッシング、コロケーション、プーリング、モニタリングといったいくつかの小さな変更で、大きな違いが生まれます。
次回、エッジ関数が遅く感じられたとき、それがコンピュートであることは稀です。十中八九、原因はデータベースにあります。通常、速度低下はそこから始まり、速度向上もそこで実現します。
引き続き議論しましょう
この記事がお役に立てば幸いです。Xで私たちをタグ付けして、構築中のものを共有してください。または、データベースとパフォーマンスについてチャットしたり、トラブルシューティングしたり、深く掘り下げたい場合は、私たちのDiscordに参加してください。
また、YouTubeで定期的にビデオでの詳細解説を投稿しています。この手のものがお好きなら、ぜひチャンネル登録してください。さらに多くの例、パフォーマンスのコツ、そしてもしかしたらサプライズ発表もあるかもしれません。そちらでお会いしましょう。
次回の投稿をお見逃しなく!
Prismaニュースレターに登録する