SQLデータベースで関連データを複数のテーブルからフェッチするのはコストがかかる場合があります。Prisma ORMでは、*データベースレベル*と*アプリケーションレベルの結合*を選択できるようになり、リレーションクエリに最適なパフォーマンスのアプローチを選ぶことができます。

目次
- Prisma ORMの新機能:最適な結合戦略を選択 🎉
joinvsquery— どちらをいつ使うべきか?- SQLデータベースにおけるリレーションの理解
- 内部では何が起こっているのか?
- 試してフィードバックを共有してください
Prisma ORMの新機能:最適な結合戦略を選択 🎉
データベースレベルの結合のサポートはPrisma ORMで最も要望の多かった機能の一つであり、この機能が新しいクエリ戦略として利用可能になったことをお知らせできることを嬉しく思います! 
include(またはselect)を使用する任意のリレーションクエリに対して、トップレベルにrelationLoadStrategyという新しいオプションが追加されました。このオプションは、次の2つの値のいずれかを受け入れます。
join(デフォルト):データベースレベルの結合戦略を使用して、データベース内のデータをマージします。query:個々のテーブルに複数のクエリを送信し、アプリケーション層でデータをマージすることにより、アプリケーションレベルの結合戦略を使用します。
新しいrelationLoadStrategyを有効にするには、まずPrisma Clientのgeneratorブロックにプレビュー機能フラグを追加する必要があります。
注:
relationLoadStrategyはPostgreSQLおよびMySQLデータベースでのみ利用可能です。
これが完了したら、この変更を有効にし、クエリでリレーションロード戦略を選択するためにprisma generateを再実行する必要があります。
新しいjoin戦略を使用する例を次に示します。
"join"がデフォルトであるため、上記のコードスニペットではrelationLoadStrategyオプションは技術的には省略可能です。ここでは説明のために表示しています。
join vs query — どちらをいつ使うべきか?
これら2つのクエリ戦略が登場した今、あなたは疑問に思うでしょう。「どちらをいつ使うべきか?」と。
Prisma ORMがPostgreSQLで利用するラテラル結合と集約結合、およびMySQLで利用する相関サブクエリにより、join戦略はほとんどのケースでより効率的である可能性が高いです(これについては後のセクションで詳しく説明します)。データベースエンジンは非常に強力で、クエリ計画の最適化に優れています。この新しいリレーションロード戦略は、その点を考慮しています。
しかし、テーブルごとに1つのクエリを実行し、アプリケーションレベルでデータをマージするために、query戦略を使用したい場合もあるかもしれません。データセットやスキーマで設定されているインデックスによっては、複数のクエリを送信する方がパフォーマンスが良い場合もあります。これらの状況を特定するには、クエリのプロファイリングとベンチマーキングが重要になります。
もう一つの考慮事項は、複雑な結合クエリによって発生するデータベースの負荷です。何らかの理由でデータベースサーバーのリソースが不足している場合、フィルターやページネーションを伴う複雑な結合クエリに必要な重い計算処理を、スケールしやすいアプリケーションサーバーに移動させたいと考えるかもしれません。
要約
- 新しい
join戦略は、ほとんどのシナリオでより効率的です。 - データセットとクエリの特性によっては、
queryの方がパフォーマンスが良いエッジケースが存在する可能性があります。これらのシナリオを特定するために、データベースクエリのプロファイリングをお勧めします。 - データベースサーバーのリソースを節約し、データのマージと変換という重い処理を、スケールしやすいアプリケーションサーバーで行いたい場合は、
queryを使用してください。
SQLデータベースにおけるリレーションの理解
Prisma ORMの結合戦略について学んだので、SQLデータベースでリレーションクエリが一般的にどのように機能するかを確認しましょう。
リレーションにおけるフラットなデータ構造とネストされたデータ構造
SQLデータベースはデータを*フラット*な(すなわち、正規化された)方法で格納します。エンティティ間のリレーションは、テーブル間の参照を指定する*外部キー*を介して表現されます。
一方、アプリケーション開発者は通常、*ネストされた*データ、つまり他のオブジェクトを任意の深さでネストできるオブジェクトを扱うことに慣れています。
これは、データがディスク上およびメモリ上で*物理的に*どのように配置されるかだけでなく、データの*メンタルモデル*や推論の仕方に関しても、大きな違いです。

アプリケーション開発者にとってリレーショナルデータは「マージ」される必要がある
関連データはデータベースに物理的に別々に保存されているため、アプリケーション開発者が慣れ親しんだネストされた構造にするためには、どこかで*マージ*する必要があります。このマージは「結合(ジョイン)」とも呼ばれます。
この結合が発生する場所は2つあります。
- 強>データベースレベル:単一のSQLクエリがデータベースに送信されます。このクエリは
JOINキーワードまたは相関サブクエリを使用して、データベースに複数のテーブル間の結合を実行させ、ネストされた構造を返します。 - 強>アプリケーションレベル:複数のクエリがデータベースに送信されます。各クエリは単一のテーブルのみにアクセスし、クエリ結果はアプリケーション層でメモリ上でマージされます。これは
v5.9.0以前のPrisma Clientがサポートしていた唯一のクエリ戦略でした。
どちらのアプローチが望ましいかは、使用されるデータベース、データセットのサイズと特性、およびクエリの複雑さによって異なります。どの戦略をいつ使用すべきかについては、読み進めてください。
内部では何が起こっているのか?
Prisma ORMは、新しいjoinリレーションロード戦略を、PostgreSQLではLATERAL結合とDBレベルのJSON集約(例:json_aggを使用)、MySQLでは相関サブクエリを使用して実装しています。
以下のセクションでは、PostgreSQLでのLATERAL結合とDBレベルのJSON集約アプローチが、単純な従来の結合よりも効率的である理由を調査します。
JSON集約によるクエリ結果の冗長性の防止
データベースレベルのJOINを使用する場合、SQLクエリを構築するためのいくつかのオプションがあります。上記のPrismaスキーマのSQLテーブル定義を考えてみましょう。
全てのユーザーとその投稿を取得するには、シンプルなLEFT JOINクエリを使用できます。
サンプルデータを使用した場合の結果は次のようになります。
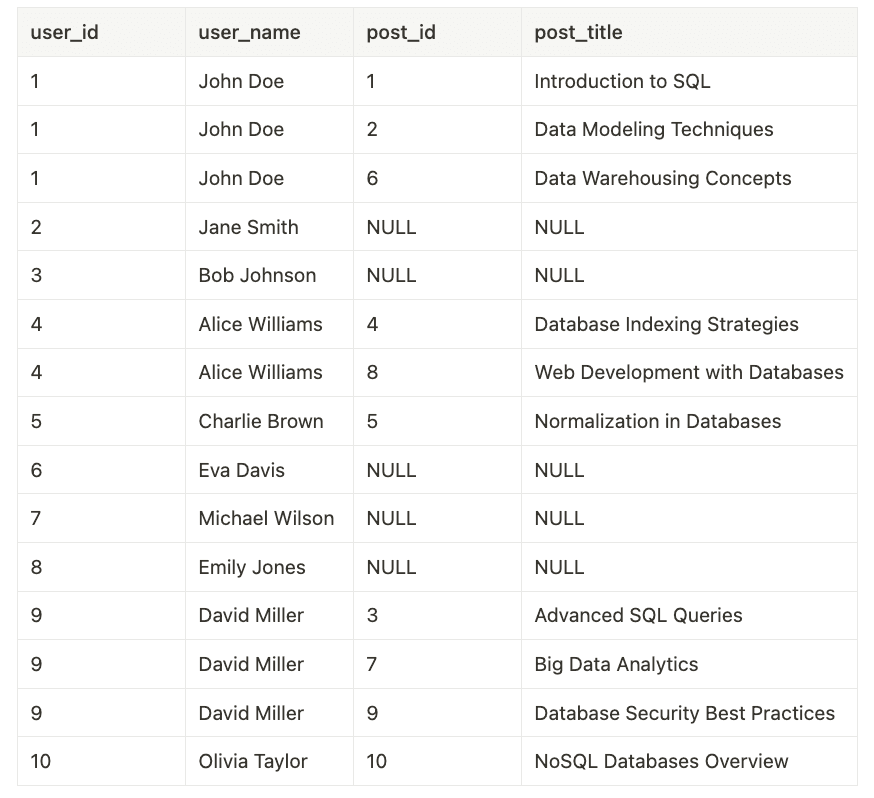
この場合、user_nameカラムに冗長性があることに注目してください。結合されるテーブルが増えるほど、この冗長性はさらに悪化します。たとえば、各コメントがPostテーブルのレコードを指すpostId外部キーを持つ別のCommentテーブルがあると仮定します。
それを表現するSQLクエリは次のとおりです。
では、最初の投稿に複数のコメントがあったと仮定しましょう。
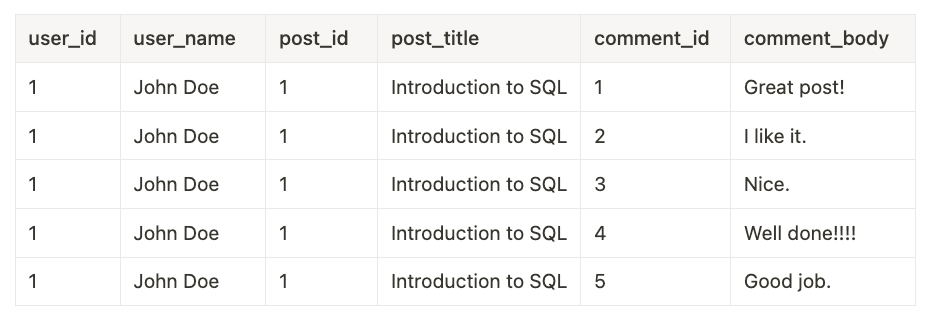
この場合、結果セットのサイズは結合されるテーブルの数に応じて指数関数的に増加します。このデータはデータベースからアプリケーションサーバーにネットワークを介して送信されるため、非常にコストがかかる可能性があります。
PrismaがデータベースレベルのJSON集約で実装したjoin戦略は、この問題を解決します。
ここに、json_aggとjson_build_objectを使用して冗長性の問題を解決し、ユーザーごとの投稿をJSON形式で返すPostgreSQLの例を示します。
今回��結果セットには冗長なデータが含まれていません。さらに、データ構造はPrisma Clientによって返される形にすでに都合よく整形されており、クエリエンジンでの結果変換という余分な作業を省くことができます。

ページネーションとフィルタリングを伴うより効率的なクエリのためのラテラル結合
リレーションクエリ(他のほとんどのクエリと同様に)は、テーブルから*全ての*データをフェッチすることはほとんどなく、フィルターやページネーションなどの追加の結果セット制約を伴います。特にページネーションは、従来の結合では非常に複雑になる可能性があります。別の例を見てみましょう。
10人のユーザーとユーザーごとに5つの投稿をフェッチする、このPrisma Clientクエリを考えてみましょう。
これを生のSQLで書く場合、サブクエリ内にLIMIT句を使用したいと考えるかもしれません。例えば、
しかし、これは機能しません。なぜなら、内部のSELECTは実際にはユーザーあたり5つの投稿を返すのではなく、合計で2つの投稿を返すため、もちろん意図した結果とは全く異なります。
従来の結合を使用する場合、row_number()関数を使用して結果セットのレコードに増分整数を割り当て、それによってページネーションの計算を手動で行うことで、この問題を解決できます。
しかし、このアプローチは非常に急速に複雑になり、ページネーションを伴うリレーションクエリを構築するには理想的ではありません。
この種のSQLクエリの維持、スケーリング、デバッグは非常に困難で、何時間もの開発時間を消費する可能性があります。
幸いなことに、新しいデータベースバージョンでは、新しい種類のクエリであるラテラル結合でこれを解決しています。
上記のクエリはLATERALキーワードを使用することで簡素化できます。
これによりクエリが読みやすくなるだけでなく、データベースエンジンはクエリの*意図*をより深く理解できるため、クエリを最適化する能力も向上する可能性が高いです。
結論
Prismaでリレーションクエリからデータを結合するためのさまざまなオプションを確認しましょう。
以前、Prismaはアプリケーションレベルの結合戦略のみをサポートしており、データベースに複数のクエリを送信し、クエリエンジン内でマージと変換の全ての作業を行って、期待されるJavaScriptオブジェクト構造に変換していました。

単純な従来の結合を使用すると、データのマージはデータベースに委ねられます。しかし、上記で説明したように、データの冗長性(リレーションクエリ内のテーブル数に応じて結果セットが指数関数的に増加する)や、フィルターやページネーションを含むクエリの複雑さといった問題があります。

これらの問題を回避するため、Prisma ORMは最新のラテラル結合をデータベースレベルのJSON集約と組み合わせて実装しています。これにより、クエリを解決し、データを期待されるJavaScriptオブジェクト構造に変換するために必要なすべての重い処理がデータベースレベルで行われます。

試してフィードバックを共有してください
新しいリレーションクエリのロード戦略をぜひお試しください。ご意見をお聞かせください。フィードバックをお寄せください!
次の投稿をお見逃しなく!
Prismaニュースレターに登録