Trygは、「360」データブローカープラットフォームのおかげで、手動で環境を設定する際に発生するオーバーヘッドを排除し、開発サイクルを加速させたことで、膨大な時間を節約しました。Prismaは、さまざまなデータソースから数十億ものレコードを民主化することを可能にした、極めて重要なテクノロジーでした。

Trygは、北欧地域最大級の損害保険会社の1つであり、個人、商業、法人市場向けに幅広い保険を提供し、年間100万件以上の保険金請求を処理しています。
多くの企業と同様に、Trygもデータのサイロ化という問題と戦いながら、より データ中心 になる必要性に直面していました。
Trygは、異なる国々にまたがる多様なデータソースを持っていました。これらのソースのTrygのデータモデルは、数十年にわたって構築されており、同じ概念でも定義が異なるため、再利用できませんでした。このため、多くの修正、回避策、妥協が必要とされました。
これらのソースのいずれかからデータを統合するには、Trygがデータを調和させる必要があり、これは時間とエラーを要するタスクです。最終的な目標は、SQLやエンティティ関係図に不慣れな人を含むすべての人にデータを利用可能にすることでした。
Trygがデータの民主化を達成することを可能にした主要なテクノロジーの1つは、 Prismaです。
Tryg 360によるデータの民主化
データの民主化を達成するには、独自のプラットフォームの実装が必要でした。そのため、Trygは Tryg 360 と呼ばれるデータブローカープラットフォームを実装し、本番環境で稼働させました。
Tryg 360は、開発者がボタンをクリックするだけで環境を起動できるようにしました。これにより、必要なアプリケーションを呼び出し、データをリアルタイムで視覚化し、アプリケーションURLを他のユーザーと共有できるようになりました。これは、すべての開発者の夢を実現するのに役立ちました。つまり、バックエンドのセットアップを管理したり、環境のロードに長い待ち時間を費やしたりする代わりに、付加価値のあるコードの記述に集中することです。
これを達成するために、Trygはデータベースクライアントと、開発者がやり取りするGraphQL APIを自動生成するPrismaの機能を採用しました。
generator APIは、prisma generateコマンドが実行されたときに作成されるアセットを決定します。
Prisma ClientとGraphQL APIの自動生成は、Trygにとって不可欠です。なぜなら、彼らは膨大な量のデータを持つ非常に複雑なモデルを扱っており、中には10K行、100万文字を超えるスキーマファイルもあるからです!
Prisma Clientを生成した後、TrygはPal.jsを使用して、他の開発者やシステムユーザーがやり取りするGraphQL APIを自動生成します。これは、GraphQLリゾルバーの手動コーディングを自動化するため、彼らにとって重要です。Pal.jsは、Prismaスキーマに基づいてGraphQL CRUDリゾルバーを生成できるジェネレーターです。
"Prismaは私たちにとって大きな技術的イネーブラーです"
Prismaによる自動化
Trygのインフラ設定は、CIを介して完全な環境をデプロイするためにいくつかのステップを要するため、比較的複雑です。このプロセスには、異なるシステムやデータベースからデータをロードし、カノニカルモデルに変換し、単一のデータベースにロードすることが含まれます。
Trygは、新しい環境をデプロイに関して以下の要件を持っていました
- スキーマに基づいてデータベースを自動生成する
- スキーマに基づいてPrisma Client APIを自動生成する
- 任意のアプリケーション、ソース、またはアプリケーションの組み合わせをデプロイする
- ワンクリックで行う
"Prismaを使った私たちのセットアップにより、すべてをコードから生成し、開発者が非常に迅速にイテレートできることを保証できました。"
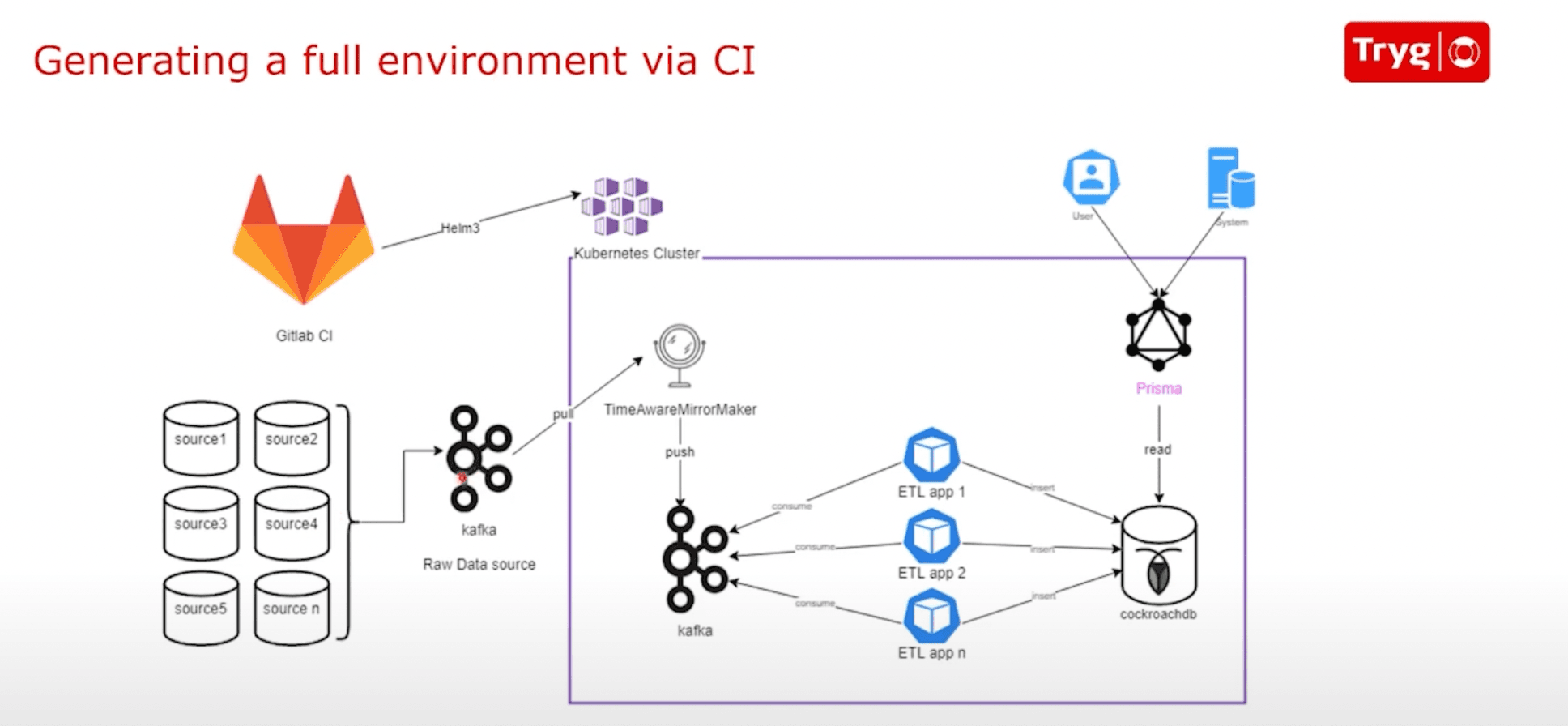
環境をデプロイするために必要なリソースは、Helmチャートで定義されています。Kubernetesは必要なリソースのプロビジョニングを処理します。リソースのプロビジョニングに関わるステップは以下の通りです。
- 変換なしで、異なるソースからの生データをライブストリーミングする。これにより、環境が作成されたときに開発者がライブデータで作業できるようになります。
- Time-Aware MirrorMakerのデプロイ – 異なるデータソースとパイプラインからいつでもデータを正しく同期する役割を担います。これはApache KafkaのMirrorMakerの実装です。
- すべてのソースからデータをロードする代わりに、必要なデータをロードするためのローカルKafkaクラスターのデプロイ。
- 特定の環境に必要なアプリケーションのデプロイ
- デプロイされたアプリケーションによるデータ変換と、Cockroachデータベースへのデータのロード
- 特定のCockroachデータベースにアクセスするPrismaを使用したアプリケーションのデプロイ
- Prismaスキーマに基づいてリゾルバーと型定義を自動生成する
CockroachDBはPostgreSQLワイヤプロトコルと互換性があるため、PrismaがまだCockroachDBの完全なサポートを提供していない場合でも、Prisma ClientはCockroachDBと通信できます。
Prismaを使用することで、TrygはデータベースクライアントとGraphQL APIを迅速に生成することができ、これにより迅速なイテレーション、単一のスキーマでのデータソースの統合、およびシステムとユーザーのデータアクセスの簡素化が可能になりました。
TrygとPrismaのビジョン
個別のデータソースを統合された場所にまとめ、開発チームがデータにアクセスできるようにする複雑なプロセスを自動化することで、TrygはFacebook、Twitter、Airbnbなどの企業が自社のために構築したPrismaデータプラットフォームのビジョンと完全に合致するアプローチを開拓しました。
Prismaの目標は、Facebook、Twitter、Airbnbのような企業が自社のために構築したアプリケーションデータプラットフォームの概念を民主化することです。私たちは、データアクセスを柔軟で安全、そして楽にスケーラブルに保つことで、あらゆる規模の開発チームや組織が最新の開発ワークフローを採用できるようにしたいと考えています。
Prisma Enterpriseに関する当社の計画について詳しく知る
結論
Prismaは、TrygがTryg 360プラットフォームを構築することを可能にする上で重要な役割を果たしてきました。次のステップとして、Trygは、ドメインモデルを洗練させるためのイベントモデリングなどの手法、イベントの考え方、タイムライン周辺での保存方法を検討しており、私たちは彼らの道のりを喜んでサポートします!
Trygの講演全体を聞いて、詳細を知る
- 得られた教訓
- Time-Aware MirrorMakerの仕組み
- TrygとPrismaの実践デモを見る
Prismaがチームの生産性向上にどのように役立つかについて詳しく知るには、Prisma Slackコミュニティに参加してください。
次回の投稿をお見逃しなく!
Prismaニュースレターに登録する