複数のチームでデータベースを共有すると、問題が発生します。マイグレーションが競合したり、クエリが肥大化したり、所有権が不明確になったりします。
この記事では、大規模チームがSQL、ORM、またはその両方を使用して、速度と自律性を維持しながら、堅牢なデータワークフローを構築する方法を詳しく解説します。展開・縮小パターン、スキーマCI、クエリ規約、生SQLを使用すべき時など、現実世界のパターンを探ります。
チームとデータベースをスケールさせているなら、この記事はあなたにぴったりです。

データワークフローがスケールで破綻する理由
チームが成長するにつれて、共有データベース環境で衝突することがよくあります。その結果、ずさんなマイグレーション、予期せぬテーブル変更、そして誰も何が誰の所有物なのかよくわからない状況が生まれます。
所有権が曖昧だと、善意の変更でさえシステム障害を引き起こす可能性があります。これは、明確に定義されたデータベースプロトコルを持たない、動きの速いプロダクトチームで特に一般的です。
一般的な問題発生の例:
- あるチームが、別のチームがまだ必要としているカラムを削除するマイグレーションをリリースする
- テーブルが互いに矛盾する目的のフィールドで肥大化する
- 1つのスキーマファイルに5人のオーナーがいて、責任の所在が不明確である
スケールアップは、技術よりも明確さにかかっていることがあります。
一つのワークフローを選び、それを退屈なものにする
チームに同じタスクを管理する複数の方法を提供することは柔軟に見えるかもしれませんが、多くの場合、一貫性の欠如と混乱を招きます。単一の「退屈な」ワークフローは、精神的な負担を軽減し、より円滑なコラボレーションを促進します。
チームがスキーマ変更を管理するために使用する3つの一般的なアプローチがあります
ヒント:DDLはData Definition Language(データ定義言語)の略で、データベース構造を定義する
CREATE、ALTER、DROPなどのSQLステートメントを指します。
チーム全体で一つのアプローチに固執してください。規律なくスタイルを混ぜると、ワークフローのデバッグが難しくなり、スケールがほぼ不可能になります。
スキーマをアプリケーションコードのように扱う
プルリクエストなしでアプリケーションコードをリリースしますか?おそらくしないでしょう。データベーススキーマも同じレベルの精査を受けるべきです。
以下のプラクティスを採用するようにしてください
- すべてのスキーマ変更をGitでバージョン管理する
- プルリクエストを通じてスキーマ変更をレビューする
- Prisma Migrate、Atlas、Liquibaseなどの差分ツールを使用して、本番環境に適用する前に変更を視覚化する
これにより透明性が生まれ、早期にミスを発見し、あらゆる進化の履歴が構築されます。
展開・縮小パターンを使用する
大規模なスキーマ変更もリスクを伴う必要はありません。展開・縮小パターンは、変更をダウンタイムを最小限に抑える非破壊的なステップに分解します。
- 展開: 新しいフィールド、テーブル、または構造を追加する
- マイグレーション: 参照や依存関係をバックフィルし、更新する
- 縮小: すべてが安全になった後にのみ、古い部分を削除または名前変更する
これにより、本番環境の破壊を防ぎ、ローリングデプロイメントをサポートし、変更が複雑な場合でもチームが稼働時間を維持するのに役立ちます。

これは、生SQL、Prisma、Rails、その他のどのシステムを使用しているかに関わらず、信頼できるパターンです。データガイドをご覧くださいして、展開・縮小パターンについてさらに学びましょう。
SQLとORMをいつ使用するかを定義する
SQLとORMは補完的なツールであり、競合するものではありません。開発速度、クエリの制御、長期的な保守性といった目標に基づいて、どちらがより適しているかを知ることが重要です。
ORMを使用するのは次の場合です
- プロダクト開発を迅速に進めたい場合
- 可読性、保守性、型安全なコードを好む場合
- ボイラープレートや反復的なタスクを抽象化することでチームに恩恵がある場合
- すべての開発者がSQLのエキスパートである必要がないようにすることで、開発のリスクを減らしたい場合
生SQLを使用するのは次の場合です
- 複雑な結合やパフォーマンスが重要なパスを最適化する場合
- クエリ、インデックス、実行計画に対してきめ細かな制御が必要な場合
- カスタムロジックに依存する、レポート機能が豊富な社内ツールを構築している場合
一つだけを選ぶ必要はありません。ほとんどの現代のアプリケーションは両方を組み合わせています。ORMを使って迅速に開発し、型安全性を保ち、パフォーマンスや柔軟性が求められる場合には生SQLに切り替えます。理想的には、それらのクエリを型付きヘルパーでラップして、保守性を維持します。
例えば、Prisma ORMのTypedSQLを使用すると、ORM呼び出しのすぐ隣で、完全なTypeScript型を伴う生SQLを使用できます。これにより、型安全性や保守性を損なうことなく、SQLの柔軟性を得られます。
いくつかの人気ツール:
Kysley (TypeScript)、Sequelize (Node.js)、Django ORM (Python)、Knex (SQLビルダー)、SQLXまたはpgxを介した生SQL (Rust)、あるいはAtlasやLiquibaseのようなマイグレーションツールを使用したSQLスクリプト。
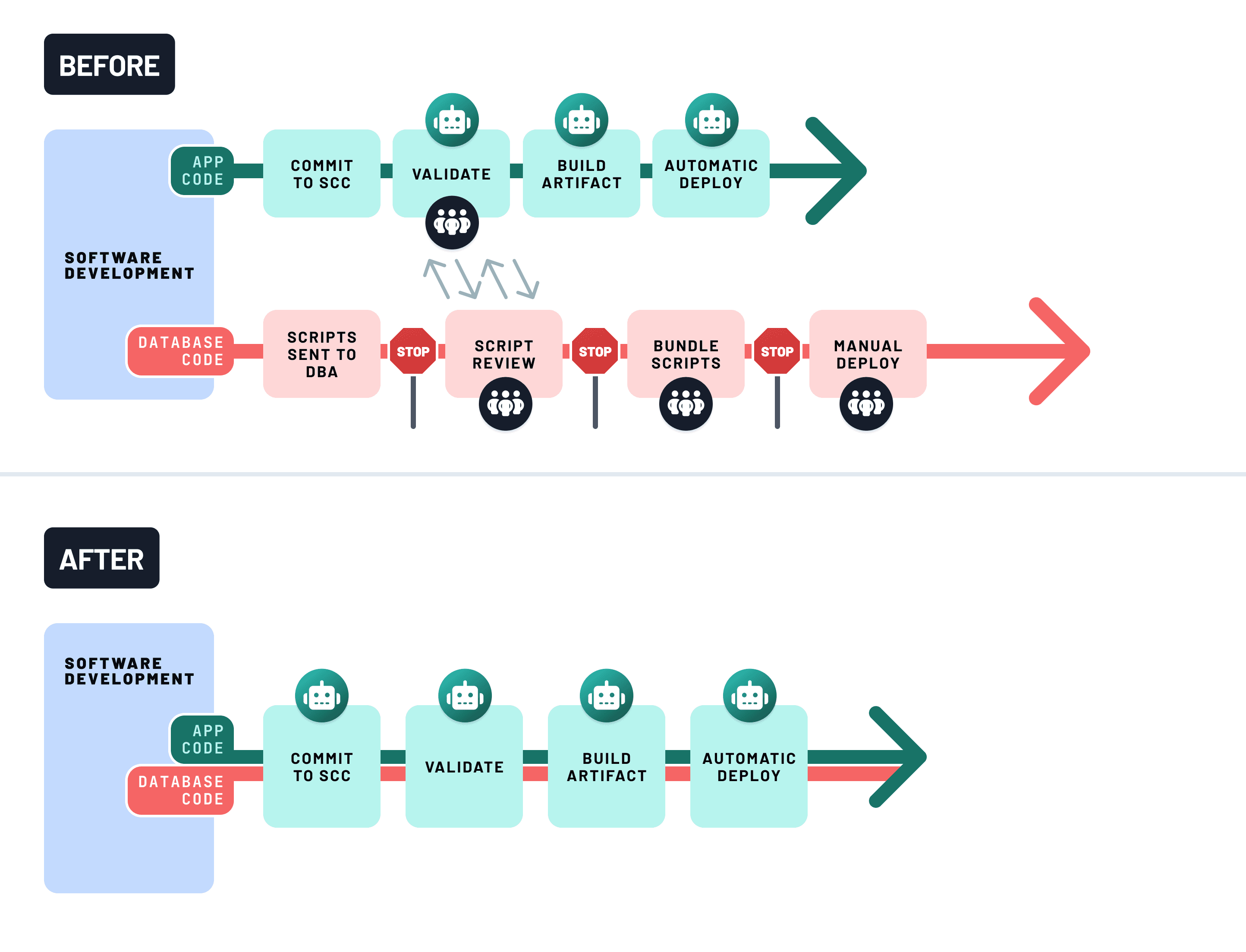
CIを使用してデータベースの安全性を確保する
ガードレールがなければ、スキーマの変更は気づかないうちに本番環境を破壊する可能性があります。継続的インテグレーション(CI)は、各変更がマージされる前に検証することで、それを防ぐのに役立ちます。
堅牢なデータベースCIパイプラインは次のことを行うべきです
- スキーマの差分をプレビューする (Prisma MigrateやAtlasのようなツールを使用して破壊的変更を検出)
- 一時的なまたはシャドウデータベースに対して結合テストを実行することで、エンドツーエンドの動作を検証する
- 破壊的なアクション(例:カラムの削除、データ損失)が検出された場合、ビルドを失敗させる
これをGitHub Actions、Docker、そして選択したマイグレーションツールで設定してください。例えば、次のようなジョブを使用します:
- クリーンなPostgreSQLコンテナを起動する
- マイグレーションを適用する
- テストスイートを実行する
- 潜在的に安全でない操作についてマイグレーション計画を解析する
これにより、本番環境に到達する前にリグレッションを検出し、スキーマの進化を展開の副作用ではなく、ワークフローの共有されレビュー可能な一部とします。
OpenAPIとSwaggerを使用して境界を定義する
チームがAPIを介してデータを交換する場合、誤解やバグを避けるためには明確な契約が不可欠です。OpenAPIは、人間とツールの両方が理解できる構造化された形式でRESTful APIを記述するための、広く採用されている仕様です。
Swaggerは、OpenAPI標準をベースに構築された人気のあるツール群です。これにより、チームは最小限の摩擦でAPIを文書化、視覚化、テストできます。
Swaggerのようなツールを使用すると、チームは次のことに役立ちます:
- APIの境界と期待される動作を明示的に定義する
- フロントエンドとバックエンドの両方で型とクライアントコードを自動生成する
- 変更を検証して、破壊的な更新を早期に検出する
- インタラクティブなドキュメントを通じてAPIエンドポイントを参照・テストする
- レスポンスのモック化と型付きクライアントの統合により、フロントエンドチームの迅速な開発を支援する
- APIを自己説明的で発見しやすいものにすることで、開発者のオンボーディングを改善する
このアプローチは、マイクロサービスアーキテクチャや、複数のチームが共有の内部APIに依存する場合に特にうまく機能します。
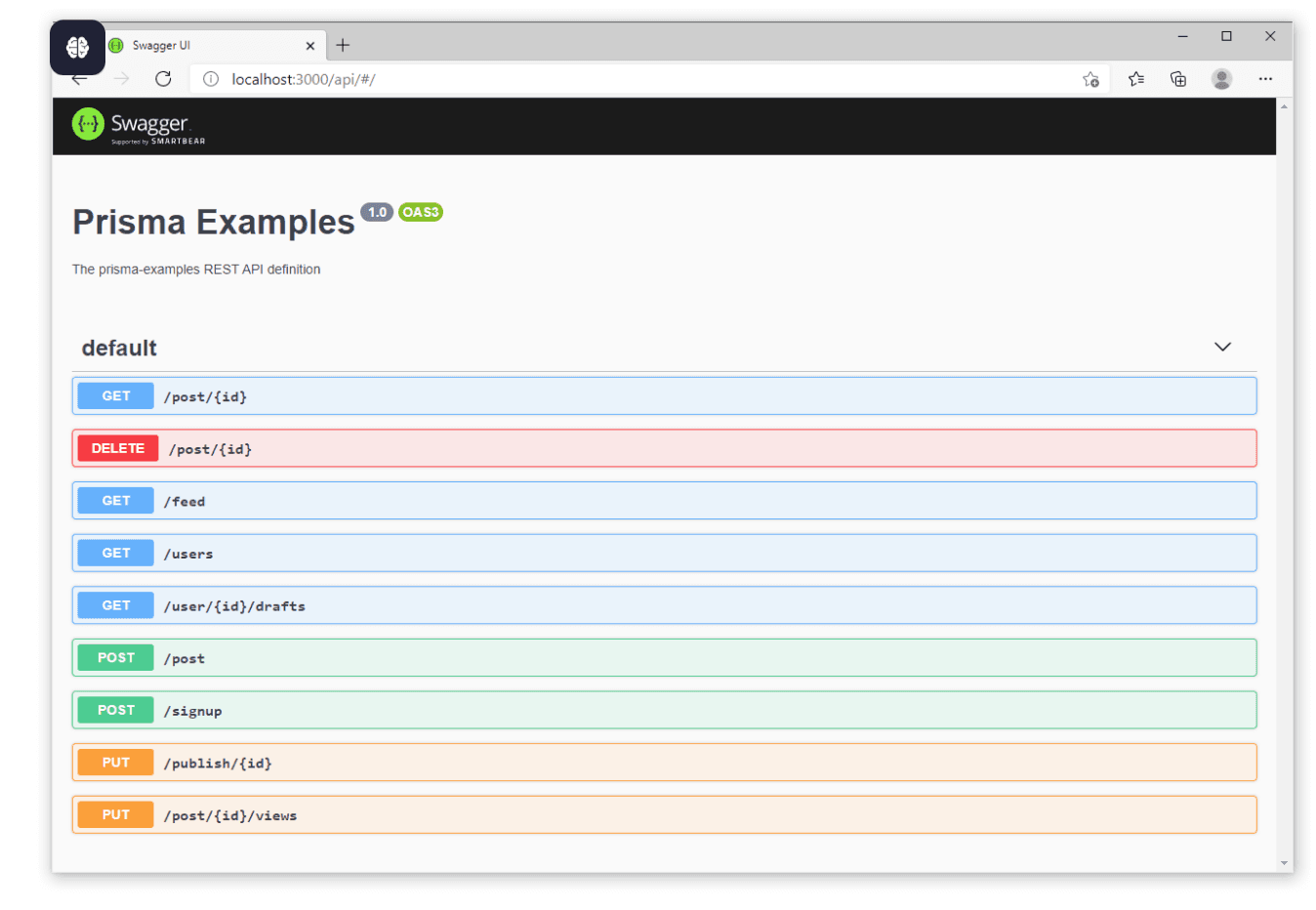
APIの動作を説明するために部族的な知識やSlackメッセージに頼る代わりに、開発者は正確で常に最新のドキュメントに基づいて、自信を持って探索、プロトタイプ作成、統合を行うことができます。
クエリを併置し、構造を標準化する
散在するロジックはスケールが困難です。一貫性のあるファイル構造は、特にチームが成長するにつれて、コードベースのナビゲート、理解、拡張を容易にします。
データアクセスロジックをmodels/、utils/、services/に分割する代わりに、ドメインごとにクエリをグループ化します。これは、技術的なレイヤーではなく、機能の境界が構造を駆動するCLEANアーキテクチャやモジュラーモノリス設計のパターンを反映しています。
これが機能する理由
- ドメインごとの明確な所有権とカプセル化を促進する
- クエリの場所を予測可能にすることでオンボーディングを加速する
- 横断的な関心事と一貫性のない抽象化を減らす
- ロジックを使用される場所に近づける — テスト、ドキュメント化、リファクタリングが容易になる
CLEANや機能ベースのアーキテクチャのようなデザインパターンは、単なる学術的なものではなく、時間の経過とともにコラボレーションを円滑にし、システムをより堅牢にします。優れた構造は、チームと製品とともにスケールします。
システム間で型を共有する
フロントエンドとバックエンド間の型の不一致は、numberをstringとして扱ったり、オプションのフィールドが欠落したりするなど、一般的なバグの原因です。これらの問題は、チームが複数の場所で同じ型を定義することで発生しやすく、重複や乖離を招きます。
コード生成は、データベーススキーマやクエリ定義から直接型を生成することで、この問題を解決します。これにより、スタック全体で同期された単一の真実の源が得られます。
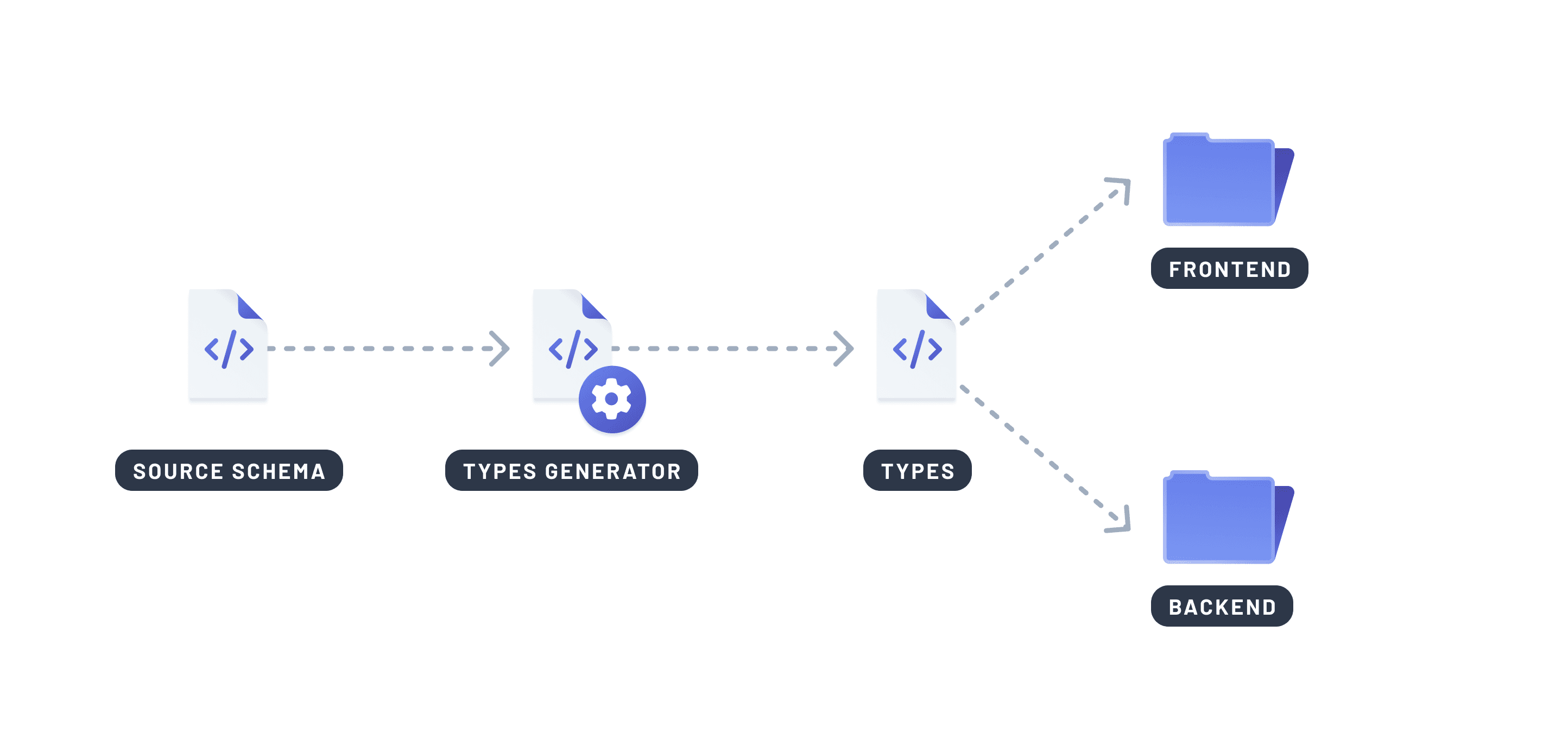
なぜ重要か
- バックエンドとフロントエンド間での型の手動重複を避ける
- 型の不一致や古い契約によって引き起こされるバグを防ぐ
- 実行時ではなくコンパイル時に正確性を強制する
- IDEのサポートとオートコンプリートの改善により、リファクタリングをより安全にする
これに役立つツールの例:Prisma ORM (TypeScript)、SQLC (Go)、SeaORM (Rust)、Pydantic (Python)
アプリケーション層で同じ型定義を共有することで、バグを減らし、開発者の自信を高め、予期せぬ問題を少なくしてより迅速にリリースできます。
AIに明白なもの(そしてそうでないものも)を見つけさせる
最新のAIツールは、品質を犠牲にすることなく、チームがより迅速に動けるように支援します。大規模言語モデル(LLM)を開発ワークフローに統合することで、面倒な作業を自動化し、微妙な点を見つけ出し、実際の問題解決に集中できます。
LLMを活用したアシスタントを使用して
- 潜在的に安全でない、または破壊的なスキーマ変更を発見する
- 迅速なレビューのためにプルリクエストの差分を要約する
- テストデータ、エッジケース、シードシナリオを生成する
- 改善点を推奨したり、プルリクエスト内で直接リスクをフラグ付けしたりする
これに役立つツールの例
Windsurf、CodiumAI、Sweep.dev (スキーマおよびPRレビュー)、GitHub Copilot、Cursor (インラインコーディングヘルプ)、OpenDevin (バックエンド自動化)。
Laravelエコシステムからの例として、Enlightnというツールがあります。これはアプリをスキャンし、パフォーマンス、セキュリティなどに関する実用的な推奨事項を提供します。
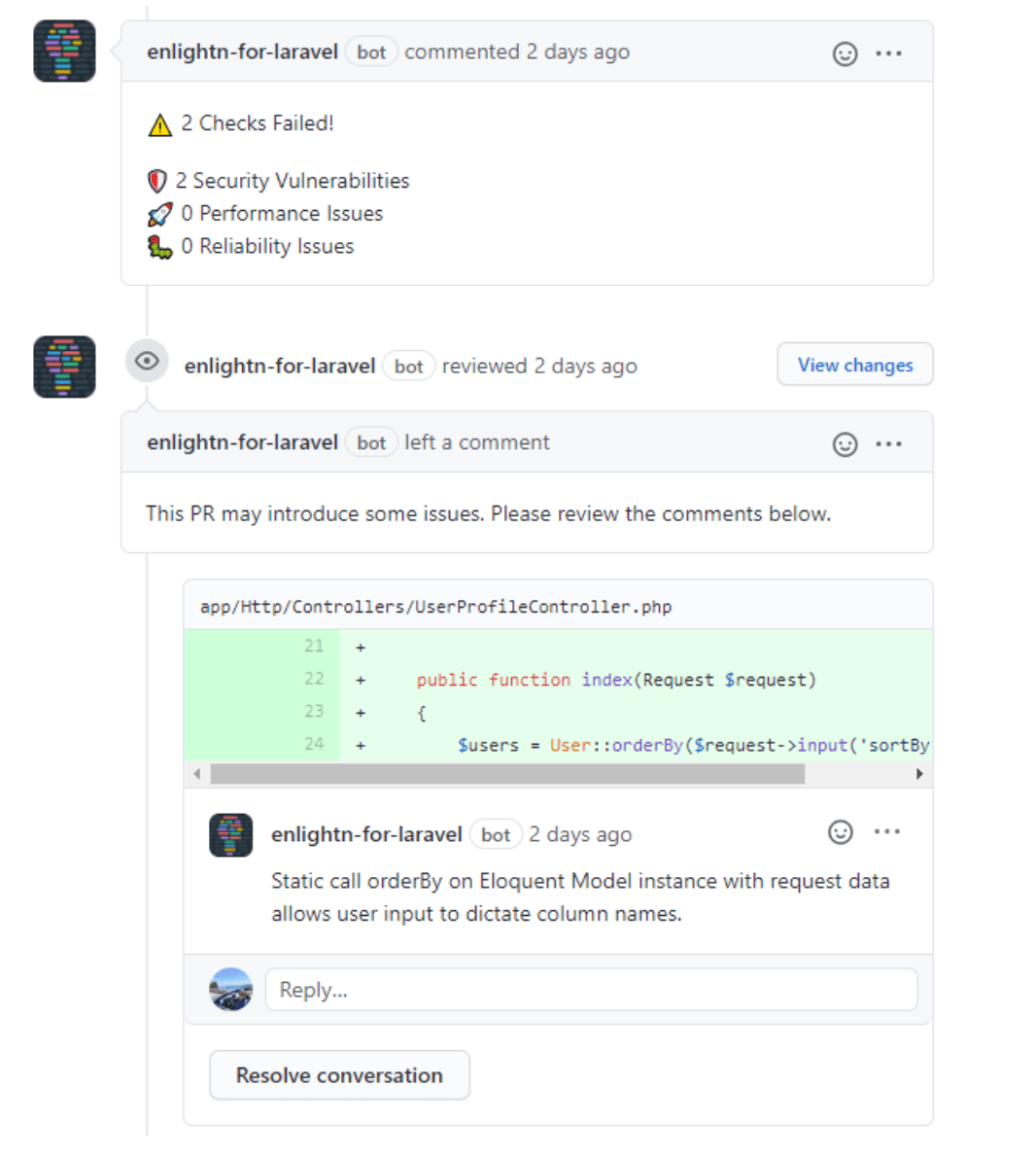
AIは速度のためだけのものではありません。それはあなたの第二の目です。賢く使えば、より安全なコードを記述し、レビューの疲労を軽減し、ルーチンタスクをオフロードすることで、全体像に集中できるようになります。
クエリの完璧さではなく、チームのベロシティを最適化する
よく調整されたクエリは価値がありますが、信頼性と一貫性をもってリリースできる能力の方が重要です。安定性を犠牲にすることなく、チーム全体がより迅速に動けるようにするワークフローを優先してください。
次のようなプロセスに焦点を当ててください:
- 安全なデフォルトと合理的な規約を奨励する
- 新しい開発者にとってオンボーディングを分かりやすくする
- ツールとCIを通じて問題を早期に検出する
- パフォーマンスとコードの明確性・保守性のバランスを取る
ベロシティ重視のプラクティスの例
ガードレール付きのORM、リンターとフォーマッター、型安全なAPI、およびクエリのリグレッションに対するCIチェックを使用します。
迅速なチームは、完全に調整されたクエリよりも多くの価値を提供します。データベースだけでなく、チームとともにスケールするワークフローを最適化してください。
TLDR: 混乱ではなくワークフローを構築する
ここまで読んでいただきありがとうございます!記憶に残るように簡単なまとめです。この表をチェックリストとしてではなく、現在の設定を診断し、洗練するためのレンズとして考えてください。スケールにおけるほとんどのデータ課題は、技術的なものよりも、明確さと整合性に関するものです。
優れたデータワークフローとは、チームが理解し、信頼し、改善できるものです。それがスケールする秘訣です。規律と明確さを選択してください。全員が物事の仕組みを理解していれば、チームはより速く、共に動けます。
会話に参加し、より良いワークフローを形成しましょう
この記事がお役に立てたなら、ぜひお聞かせください。Xで私たちをタグ付けして、あなたが構築しているものを共有してください。データベースやパフォーマンスについて話したり、トラブルシューティングしたり、深く議論したい場合は、私たちのDiscordに参加してください。
また、YouTubeで定期的にビデオによる深掘りを投稿しています。もし興味があれば、ぜひチャンネル登録してください。さらに多くの例、パフォーマンスのコツ、そしてサプライズ発表があるかもしれません。そこでお会いしましょう。
次の投稿をお見逃しなく!
Prismaニュースレターに登録