Prisma ORMはORMなのか?
質問に簡潔に答えると、はい、Prisma ORMは従来のORMとは根本的に異なる新しいタイプのORMであり、従来関連付けられていた多くの問題に悩まされることはありません。
従来のORMは、プログラミング言語の*モデルクラス*にテーブルをマッピングすることで、リレーショナルデータベースを操作するためのオブジェクト指向な方法を提供します。このアプローチは、オブジェクト関係インピーダンスミスマッチに起因する多くの問題を引き起こします。
Prisma ORMは、それとは根本的に異なる動作をします。Prisma ORMでは、宣言的なPrismaスキーマでモデルを定義します。これは、データベーススキーマとプログラミング言語のモデルの唯一の真の情報源として機能します。アプリケーションコードでは、Prisma Clientを使用して、複雑なモデルインスタンスを管理するオーバーヘッドなしに、タイプセーフな方法でデータベースのデータを読み書きできます。これにより、Prisma Clientが常にプレーンなJavaScriptオブジェクトを返すため、データクエリのプロセスがはるかに自然で予測可能になります。
この記事では、ORMのパターンとワークフロー、Prisma ORMがデータマッパーパターンをどのように実装しているか、そしてPrisma ORMのアプローチの利点について、より詳しく学びます。
ORMとは?
ORMにすでに慣れている場合は、Prisma ORMに関する次のセクションにスキップしても構いません。
ORMパターン - Active Recordとデータマッパー
ORMは、高レベルのデータベース抽象化を提供します。これらは、オブジェクトを介してプログラム的なインターフェースを公開し、データベースの複雑さの一部を隠しながら、データの作成、読み取り、削除、操作を可能にします。
ORMの考え方は、データベースのテーブルにマッピングされるクラスとしてモデルを定義することです。これらのクラスとそのインスタンスは、データベースのデータを読み書きするためのプログラム的なAPIを提供します。
一般的なORMパターンには、オブジェクトとデータベースの間でデータを転送する方法が異なるActive Recordとデータマッパーの2つがあります。どちらのパターンもクラスを主要な構成要素として定義する必要がありますが、両者の最も顕著な違いは、データマッパーパターンがアプリケーションコード内のインメモリオブジェクトをデータベースから切り離し、データマッパー層を使用して両者の間でデータを転送することです。実際には、データマッパーを使用すると、インメモリオブジェクト(データベース内のデータを表す)はデータベースが存在することさえ知りません。
Active Record
Active Record ORMは、モデルクラスをデータベーステーブルにマッピングします。ここでは、両方の表現の構造が密接に関連しており、たとえば、モデルクラスの各フィールドはデータベーステーブルに対応する列を持ちます。モデルクラスのインスタンスはデータベースの行をラップし、データとアクセスロジックの両方を持ち、データベース内の変更を永続化する処理を行います。さらに、モデルクラスはモデル内のデータに特有のビジネスロジックを持つことができます。
モデルクラスには通常、次のようなメソッドがあります
- SQLクエリからモデルのインスタンスを構築する。
- 後でテーブルに挿入するための新しいインスタンスを構築する。
- 一般的に使用されるSQLクエリをラップし、Active Recordオブジェクトを返す。
- データベースを更新し、Active Record内のデータを挿入する。
- フィールドの取得と設定を行う。
- ビジネスロジックを実装する。
データマッパー
データマッパー ORMは、Active Recordとは対照的に、アプリケーションのインメモリデータ表現をデータベースの表現から分離します。この分離は、マッピングの責任を2種類のクラスに分けることによって達成されます
- エンティティクラス: データベースの知識を持たない、アプリケーションのインメモリエンティティ表現
- マッパークラス: これらは2つの責任を持ちます
- 2つの表現間でデータを変換する。
- データベースからデータを取得し、データベースの変更を永続化するために必要なSQLを生成する。
データマッパーORMは、コードで実装された問題ドメインとデータベースの間でより大きな柔軟性を可能にします。これは、データマッパーパターンによって、データベースの実装方法を隠すことができるためであり、これはデータマッピング層全体の後ろにあるドメインを考える理想的な方法ではありません。
従来のデータマッパーORMがこれを行う理由の1つは、2つの責任が異なるチーム、例えばDBAとバックエンド開発者によって処理される組織構造にあります。
実際には、すべてのデータマッパーORMがこのパターンに厳密に従っているわけではありません。例えば、Active Recordとデータマッパーの両方をサポートするTypeScriptエコシステムで人気のORMであるTypeORMは、データマッパーに対して以下のアプローチを取っています
- エンティティクラスはデコレータ (
@Column) を使用してクラスのプロパティをテーブルの列にマッピングし、データベースを認識します。 - マッパークラスの代わりに、リポジトリクラスがデータベースのクエリに使用され、カスタムクエリを含む場合があります。リポジトリはデコレータを使用して、エンティティのプロパティとデータベースの列間のマッピングを決定します。
データベース内の以下のUserテーブルがある場合

対応するエンティティクラスは次のようになります
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
}
スキーママイグレーションワークフロー
データベースを利用するアプリケーションを開発する上で中心となるのは、新機能に対応し、解決しようとしている問題により適するようにデータベーススキーマを変更することです。このセクションでは、スキーママイグレーションとは何か、そしてそれがワークフローにどのように影響するかについて議論します。
ORMは開発者とデータベースの間に位置するため、ほとんどのORMはデータベーススキーマの作成と変更を支援するためのマイグレーションツールを提供します。
マイグレーションとは、データベーススキーマをある状態から別の状態へ移行するための一連の手順です。最初のマイグレーションでは通常、テーブルとインデックスが作成されます。その後のマイグレーションでは、列の追加または削除、新しいインデックスの導入、または新しいテーブルの作成が行われる場合があります。マイグレーションツールに応じて、マイグレーションはSQLステートメントの形式、またはSQLステートメントに変換されるプログラムコードの形式(ActiveRecordやSQLAlchemyのように)で行われます。
データベースには通常データが含まれているため、マイグレーションはスキーマ変更をより小さな単位に分解するのに役立ち、意図しないデータ損失を防ぎます。
プロジェクトをゼロから開始すると仮定した場合、完全なワークフローは次のようになります。まず、データベーススキーマにUserテーブルを作成するマイグレーションを作成し、上記の例のようにUserエンティティクラスを定義します。
その後、プロジェクトが進むにつれて、Userテーブルに新しいsalutation列を追加したいと決定した場合、テーブルを変更してsalutation列を追加する別のマイグレーションを作成することになります。
TypeORMのマイグレーションでそれがどのように見えるか見てみましょう
import { MigrationInterface, QueryRunner } from 'typeorm'
export class UserRefactoring1604448000 implements MigrationInterface {
async up(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" ADD COLUMN "salutation" TEXT`)
}
async down(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" DROP COLUMN "salutation"`)
}
}
マイグレーションが実行され、データベーススキーマが変更されたら、新しいsalutation列に対応するためにエンティティクラスとマッパークラスも更新する必要があります。
TypeORMでは、これはUserエンティティクラスにsalutationプロパティを追加することを意味します
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
@Column()
salutation: string
}
このような変更の同期は、ORMでは課題となることがあります。なぜなら、変更が手動で適用され、プログラム的に容易に検証できないためです。既存の列の名前変更はさらに面倒で、列への参照を検索して置換する作業が必要になる場合があります。
注: Djangoのmakemigrations CLIは、モデルの変更を検査することでマイグレーションを生成します。これはPrisma ORMと同様に、同期の問題を解消します。
要約すると、スキーマを進化させることは、アプリケーション構築の重要な部分です。ORMを使用する場合、スキーマを更新するワークフローには、マイグレーションツールを使用してマイグレーションを作成し、その後、対応するエンティティクラスとマッパークラスを更新する(実装による)作業が含まれます。ご覧のとおり、Prisma ORMはこれとは異なるアプローチを取っています。
マイグレーションが何であり、開発ワークフローにどのように組み込まれるかを見たところで、ORMの利点と欠点について詳しく学びます。
ORMの利点
開発者がORMを使用するのにはいくつかの理由があります
- ORMはドメインモデルの実装を容易にします。ドメインモデルとは、ビジネスロジックの振る舞いとデータを組み込んだオブジェクトモデルです。言い換えれば、データベース構造やSQLのセマンティクスではなく、実際のビジネスコンセプトに集中できるようになります。
- ORMはコード量を減らすのに役立ちます。一般的なCRUD(作成、読み取り、更新、削除)操作のための繰り返し的なSQLステートメントの記述や、SQLインジェクションなどの脆弱性を防ぐためのユーザー入力のエスケープから解放されます。
- ORMでは、ほとんど、あるいはまったくSQLを記述する必要がありません(複雑度によっては、奇妙な生のクエリを記述する必要がある場合もあります)。これは、SQLに慣れていないがデータベースを扱いたい開発者にとって有益です。
- 多くのORMは、データベース固有の詳細を抽象化します。理論的には、これによりORMを使用することで、あるデータベースから別のデータベースへの変更が容易になります。ただし、実際にはアプリケーションが使用するデータベースを変更することはめったにないことに注意する必要があります。
生産性向上を目指すすべての抽象化と同様に、ORMの使用にも欠点があります。
ORMの欠点
ORMの欠点は、使い始めたばかりでは必ずしも明らかではありません。このセクションでは、一般的に認められているもののいくつかを取り上げます
- ORMを使用すると、データベーステーブルのオブジェクトグラフ表現が形成され、オブジェクト関係インピーダンスミスマッチにつながる可能性があります。これは、解決しようとしている問題が、リレーショナルデータベースに簡単にマッピングできない複雑なオブジェクトグラフを形成する場合に発生します。リレーショナルデータベース内のデータと、インメモリ(オブジェクトを使用)の2つの異なるデータ表現間で同期を取ることは非常に困難です。これは、オブジェクトがリレーショナルデータベースのレコードと比較して、互いに関連付けられる方法がより柔軟で多様であるためです。
- ORMは問題に関連する複雑さを処理しますが、同期の問題は解消されません。データベーススキーマやデータモデルへの変更は、反対側にもマッピングし直す必要があります。この負担はしばしば開発者にあります。プロジェクトに取り組むチームの文脈では、データベーススキーマの変更には調整が必要です。
- ORMは、カプセル化された複雑さのために、広範なAPIサーフェスを持つ傾向があります。SQLを記述する必要がないという利点の裏側には、ORMの使い方を学ぶのに多くの時間を費やすという点があります。これはほとんどの抽象化に当てはまりますが、データベースがどのように機能するかを理解していなければ、遅いクエリを改善することは困難な場合があります。
- SQLが提供する柔軟性のため、一部の複雑なクエリはORMでサポートされていません。この問題は、生のSQLクエリ機能によって緩和されます。この機能では、SQLステートメント文字列をORMに渡し、ORMがクエリを実行します。
ORMのコストと利点について説明したところで、Prisma ORMとは何か、そしてそれがどのように機能するかをよりよく理解できるようになります。
Prisma ORM
Prisma ORMは、アプリケーション開発者にとってデータベースとの連携を容易にする次世代ORMであり、以下のツールを備えています
- Prisma Client: アプリケーションで使用するための、自動生成され型安全なデータベースクライアント。
- Prisma Migrate: 宣言的なデータモデリングとマイグレーションツール。
- Prisma Studio: データベース内のデータを参照・管理するためのモダンなGUI。
注: Prisma Clientは最も主要なツールであるため、しばしば単にPrismaと呼びます。
これら3つのツールは、データベーススキーマ、アプリケーションのオブジェクトスキーマ、そして両者の間のマッピングについて、Prismaスキーマを唯一の真の情報源として使用します。これはあなたが定義するものであり、Prisma ORMを設定する主な方法です。
Prisma ORMは、型安全性、豊富なオートコンプリート、関連をフェッチするための自然なAPIなどの機能により、構築するソフトウェアに対して生産性と自信をもたらします。
次のセクションでは、Prisma ORMがデータマッパーORMパターンをどのように実装しているかについて学びます。
Prisma ORMがデータマッパーパターンをどのように実装するか
記事の前半で述べたように、データマッパーパターンは、データベースとアプリケーションが異なるチームによって所有されている組織によく適合します。
マネージドデータベースサービスとDevOpsプラクティスを備えた現代のクラウド環境の台頭により、より多くのチームが、データベースや運用上の懸念を含む完全な開発サイクルをチームが所有する、クロスファンクショナルなアプローチを採用しています。
Prisma ORMは、DBスキーマとオブジェクトスキーマの同時進化を可能にし、それによってそもそも逸脱の必要性を減らしつつ、@map属性を使用してアプリケーションとデータベースをある程度分離した状態に保つことができます。これは制限のように見えるかもしれませんが、ドメインモデルの進化(オブジェクトスキーマを介して)が後からデータベースに強制されるのを防ぎます。
Prisma ORMのデータマッパーパターンの実装が従来のデータマッパーORMと概念的にどのように異なるかを理解するために、それらの概念と構成要素を簡単に比較します
| 概念 | 説明 | 従来のORMにおける構成要素 | Prisma ORMにおける構成要素 | Prisma ORMにおける唯一の真の情報源 |
|---|---|---|---|---|
| オブジェクトスキーマ | アプリケーション内のインメモリデータ構造 | モデルクラス | 生成されたTypeScript型 | Prismaスキーマ内のモデル |
| データマッパー | オブジェクトスキーマとデータベースの間で変換を行うコード | マッパークラス | Prisma Client内の生成された関数 | Prismaスキーマ内の@map属性 |
| データベーススキーマ | 手書きまたはプログラム的なAPIで記述されたSQL | Prisma Migrateによって生成されたSQL | Prismaスキーマ | Prisma ORMはデータマッパーパターンに適合しており、以下の利点が追加されています |
Prismaスキーマに基づいてPrisma Clientを生成することで、クラス定義とマッピングロジックの定型的な記述を減らします。
- アプリケーションオブジェクトとデータベーススキーマ間の同期の課題を解消します。
- データベースマイグレーションは、Prismaスキーマから派生するため、第一級の存在です。
- Prisma ORMのデータマッパーアプローチの背後にある概念について説明したところで、Prismaスキーマが実際にどのように機能するかを見ていきましょう。
Prismaスキーマ
Prismaのデータマッパーパターンの実装の中心にあるのは、以下の責任における唯一の真の情報源であるPrismaスキーマです
Prismaがデータベースに接続する方法を設定する。
- Prisma Client(アプリケーションコードで使用するための型安全なORM)を生成する。
- Prisma Migrateを使用してデータベーススキーマを作成し、進化させる。
- アプリケーションオブジェクトとデータベース列間のマッピングを定義する。
- Prisma ORMにおけるモデルは、Active Record ORMとはわずかに異なる意味を持ちます。Prisma ORMでは、モデルはPrismaスキーマ内で抽象的なエンティティとして定義され、テーブル、リレーション、および列とPrisma Clientのプロパティ間のマッピングを記述します。
例として、ブログのPrismaスキーマを示します
上記の例の内訳は次のとおりです
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
The datasource block defines the connection to the database.
generatorブロックは、Prisma ORMにTypeScriptとNode.js用のPrisma Clientを生成するように指示します。PostとUserモデルはデータベーステーブルにマッピングされます。- 2つのモデルは1対多のリレーションを持ち、各
Userは複数の関連するPostを持つことができます。 - モデルの各フィールドには型があり、例えば
idはInt型です。 - フィールドには、定義するためのフィールド属性を含めることができます
@id属性を持つプライマリキー。@unique属性を持つユニークキー。@default属性を持つデフォルト値。@map属性によるテーブルの列とPrisma Clientのフィールド間のマッピング。例えば、contentフィールド(Prisma Clientでアクセス可能)は、post_contentデータベース列にマッピングされます。UserとPostのリレーションは、以下の図で視覚化できます
Prisma ORMレベルでは、UserとPostのリレーションは以下で構成されます
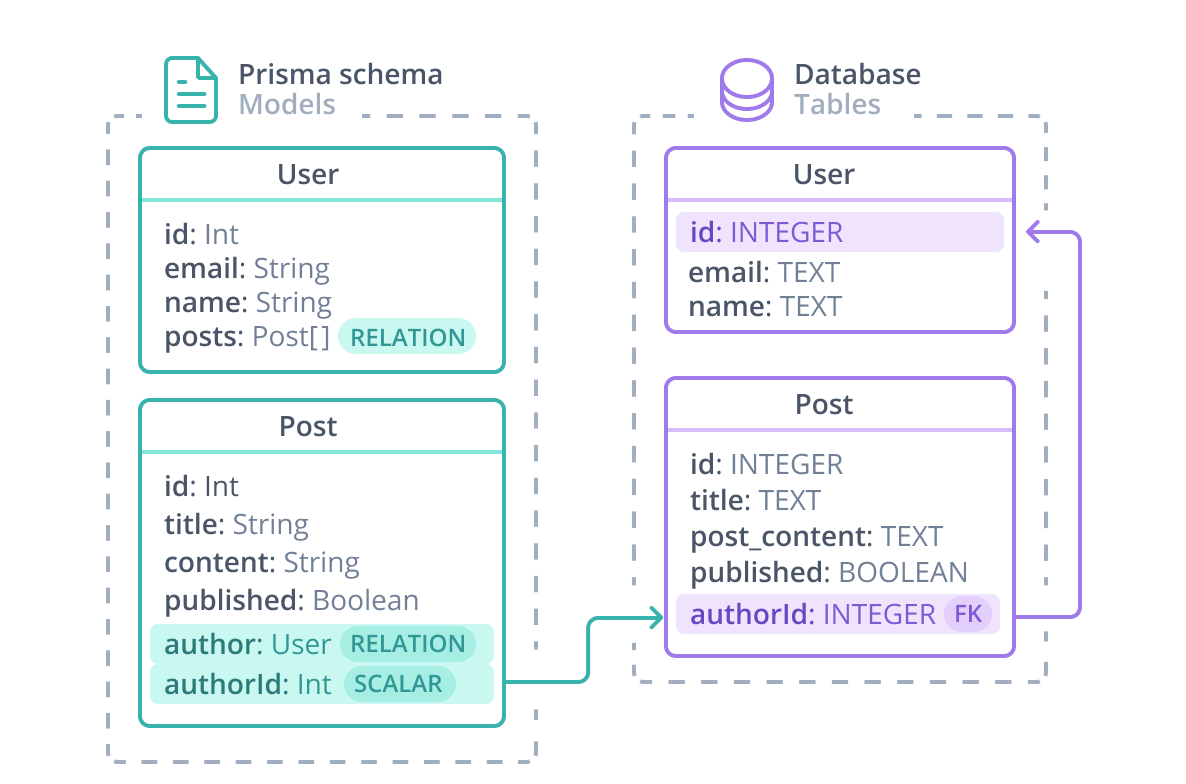
スカラー型のauthorIdフィールド。これは@relation属性によって参照されます。このフィールドはデータベーステーブルに存在し、PostとUserを接続する外部キーです。
- 2つのリレーションフィールド:
authorとpostsはデータベーステーブルには存在しません。リレーションフィールドはPrisma ORMレベルでモデル間の接続を定義し、Prismaスキーマと生成されたPrisma Clientにのみ存在し、そこでリレーションにアクセスするために使用されます。 - Prismaスキーマの宣言的な性質は簡潔であり、データベーススキーマとPrisma Clientにおける対応する表現を定義することを可能にします。
次のセクションでは、Prisma ORMがサポートするワークフローについて学びます。
Prisma ORMワークフロー
Prisma ORMのワークフローは、従来のORMとは少し異なります。Prisma ORMは、新しいアプリケーションをゼロから構築する場合、または段階的に導入する場合に使用できます。
新規アプリケーション(グリーンフィールド):まだデータベーススキーマがないプロジェクトは、Prisma Migrateを使用してデータベーススキーマを作成できます。
- 既存アプリケーション(ブラウンフィールド):すでにデータベーススキーマを持つプロジェクトは、Prisma ORMによってイントロスペクトされ、PrismaスキーマとPrisma Clientを生成できます。このユースケースは既存のマイグレーションツールと連携し、段階的な導入に役立ちます。マイグレーションツールとしてPrisma Migrateに切り替えることも可能ですが、これはオプションです。
- どちらのワークフローでも、Prismaスキーマが主要な設定ファイルとなります。
既存データベースを持つプロジェクトでの段階的導入のためのワークフロー
ブラウンフィールドプロジェクトには、通常、何らかのデータベース抽象化とスキーマがすでに存在します。Prisma ORMは、既存のデータベースをイントロスペクトして、既存のデータベーススキーマを反映するPrismaスキーマを取得し、Prisma Clientを生成することで、そのようなプロジェクトと統合できます。このワークフローは、すでに使用している可能性のあるあらゆるマイグレーションツールおよびORMと互換性があります。段階的に評価および採用したい場合は、このアプローチを並行導入戦略の一部として使用できます。
このワークフローと互換性のあるセットアップの非網羅的なリスト
CREATE TABLEおよびALTER TABLEを使用してデータベーススキーマを作成・変更するプレーンなSQLファイルを使用するプロジェクト。
- db-migrateやUmzugなどのサードパーティ製マイグレーションライブラリを使用するプロジェクト。
- すでにORMを使用しているプロジェクト。この場合、ORMを介したデータベースアクセスは変更されず、生成されたPrisma Clientを段階的に導入できます。
- 実際には、既存のDBをイントロスペクトしてPrisma Clientを生成するために必要な手順は次のとおりです
datasource(この場合、既存のDB)とgeneratorを定義するschema.prismaを作成します
prisma db pullを実行して、データベーススキーマから派生したモデルでPrismaスキーマを生成します。
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client-js"
}
- (オプション)Prisma Clientとデータベース間のフィールドとモデルのマッピングをカスタマイズします。
prisma generateを実行します。- Prisma ORMは
node_modulesフォルダ内にPrisma Clientを生成し、そこからアプリケーションにインポートできます。より詳細な使用方法については、Prisma Client APIのドキュメントを参照してください。
要約すると、Prisma Clientは、既存のデータベースとツールを備えたプロジェクトに並行導入戦略の一環として統合できます。新しいプロジェクトでは、次に詳述する別のワークフローを使用します。
新規プロジェクトのワークフロー
Prisma ORMは、サポートするワークフローの点で他のORMとは異なります。新しいデータベーススキーマを作成および変更するために必要な手順を詳しく見ると、Prisma Migrateを理解するのに役立ちます。
Prisma Migrateは、宣言的なデータモデリングとマイグレーションのためのCLIです。ORMの一部として提供されるほとんどのマイグレーションツールとは異なり、ある状態から別の状態へ移行するための操作ではなく、現在のスキーマを記述するだけで済みます。Prisma Migrateは操作を推論し、SQLを生成してマイグレーションを実行します。
この例では、上記のブログの例と同様の新しいデータベーススキーマを持つ新しいプロジェクトでPrisma ORMを使用する方法を示します
Prismaスキーマを作成します
prisma migrateを実行して、マイグレーション用のSQLを生成し、データベースに適用して、Prisma Clientを生成します。
// schema.prisma
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client-js"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
- データベーススキーマへのさらなる変更の場合
Prismaスキーマに変更を適用します。例えば、UserモデルにregistrationDateフィールドを追加します。
- もう一度
prisma migrateを実行します。 - 最後のステップでは、Prismaスキーマにフィールドを追加し、Prisma Migrateを使用してデータベーススキーマを目的の状態に変換することで、宣言的マイグレーションがどのように機能するかを示しています。マイグレーションが実行されると、Prisma Clientは自動的に再生成され、更新されたスキーマが反映されます。
Prisma Migrateを使用しないが、新しいプロジェクトで型安全な生成済みPrisma Clientを使用したい場合は、次のセクションを参照してください。
Prisma Migrateを使用しない新規プロジェクトの代替手段
Prisma Migrateの代わりにサードパーティのマイグレーションツールを使って新しいプロジェクトでPrisma Clientを使用することは可能です。例えば、新しいプロジェクトでは、Node.jsのマイグレーションフレームワークであるdb-migrateを使用してデータベーススキーマとマイグレーションを作成し、クエリにはPrisma Clientを使用するという選択肢があります。本質的には、これは既存データベースのワークフローでカバーされています。
Prisma Clientでデータにアクセスする
これまで、この記事ではPrisma ORMの背後にある概念、データマッパーパターンの実装、およびサポートされているワークフローについて説明しました。この最後のセクションでは、Prisma Clientを使用してアプリケーションでデータにアクセスする方法について説明します。
Prisma Clientによるデータベースへのアクセスは、公開されているクエリメソッドを介して行われます。すべてのクエリはプレーンなJavaScriptオブジェクトを返します。上記のブログスキーマを考慮すると、ユーザーのフェッチは次のようになります
このクエリでは、findUnique()メソッドを使用してUserテーブルから単一行を取得します。デフォルトでは、Prisma ORMはUserテーブル内のすべてのスカラーフィールドを返します。
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
})
注: この例では、Prisma Clientが提供する型安全機能を最大限に活用するためにTypeScriptを使用しています。ただし、Prisma ORMはNode.jsのJavaScriptでも動作します。
Prisma Clientは、Prismaスキーマからコードを生成することで、クエリと結果を構造型にマッピングします。これにより、生成されたPrisma Clientでは
userに関連する型が提供されます。
これにより、存在しないフィールドにアクセスすると型エラーが発生することが保証されます。より広く言えば、これはすべてのクエリの結果の型がクエリ実行前に既知であり、エラーの捕捉に役立つことを意味します。例えば、次のコードスニペットは型エラーを発生させます
export type User = {
id: number
email: string
name: string | null
}
リレーションのフェッチ
console.log(user.lastName) // Property 'lastName' does not exist on type 'User'.
Prisma Clientでのリレーションのフェッチは、includeオプションを使用して行われます。例えば、ユーザーとその投稿をフェッチするには、次のように行います
このクエリにより、userの型にはPostも含まれるようになり、posts配列フィールドでアクセスできます
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
include: {
posts: true,
},
})
この例は、Prisma ClientのCRUD操作用APIのごく一部にすぎません。詳細はドキュメントでご確認ください。主な考え方は、すべてのクエリと結果が型によって裏付けられており、リレーションのフェッチ方法を完全に制御できるということです。
console.log(user.posts[0].title)
結論
要約すると、Prisma ORMは従来のORMとは異なり、一般的に関連付けられている問題に悩まされることのない新しいタイプのデータマッパーORMです。
従来のORMとは異なり、Prisma ORMでは、データベーススキーマとアプリケーションモデルの宣言的な唯一の真の情報源であるPrismaスキーマを定義します。Prisma Client内のすべてのクエリはプレーンなJavaScriptオブジェクトを返すため、データベースとの対話プロセスがはるかに自然で予測可能になります。
Prisma ORMは、新規プロジェクトの開始と既存プロジェクトへの導入のための2つの主要なワークフローをサポートしています。どちらのワークフローでも、設定の主要な手段はPrismaスキーマを介して行われます。
すべての抽象化と同様に、Prisma ORMと他のORMは、異なる仮定のもとでデータベースの基礎となる詳細の一部を隠蔽します。
これらの違いとあなたのユースケースはすべて、ワークフローと導入コストに影響します。それらがどのように異なるかを理解することで、情報に基づいた意思決定ができるようになることを願っています。
このページをGitHubで編集