複数のテーブルからデータを結合することは複雑なトピックです。主な戦略として、データベースレベルとアプリケーションレベルの2つがあります。Prisma ORMは両方のオプションを提供しています。この記事では、それぞれのトレードオフについて学び、あなたのユースケースに最適な戦略を選択できるようにします。

はじめに
Prisma ORMが当初アプリケーションレベルのJOINのみを提供していたのはなぜですか?
Prisma ORMは当初、*アプリケーションレベル*のJOIN戦略のみを提供していました。この選択にはいくつかの理由がありました。
- データベースエンジン間で同じ結合戦略を使用できるため、移植性が確保されます。
- コストのかかる操作をアプリケーション層に移行することで、システム全体のスケーラビリティが向上します(アプリケーション層はデータベースよりも拡張が容易で安価です)。
- アプリケーションとデータベースが同じクラウドリージョンに併置されるのが一般的なクラウドネイティブおよびサーバーレスのユースケースでは、データベースへの追加の往復によるオーバーヘッドは無視できます。
- 数百万行のデータと、フィルターやページネーションなどの追加機能を使用する深くネストされたクエリを伴う高性能ユースケース。
- 各クエリが単一のテーブルのみを対象とするため、クエリのデバッグが簡単になります(複雑なクエリプランを理解したりデバッグしたりする必要がありません)。
- データベースの責任を単純な操作に限定し、データベースのクエリプランナーと実行時最適化に依存するクエリパフォーマンスの大きな変動を防ぐことで、予測可能なパフォーマンスを実現します。
2024年2月、Prisma ORMは、LATERAL JOINやJSON集約といった最新のデータベース機能を使用するスマートなDBレベルJOINを代替戦略として追加しました。このアプローチは、アプリケーションサーバーとDBサーバーが互いに離れていて、追加のネットワーク往復にかかるコストがクエリ全体のレイテンシに大きく影響する場合に有利です。
最終的に、これらのアプローチにはそれぞれ独自のトレードオフがあり、この記事の残りの部分でそれらを明らかにし、リレーションクエリに最適な戦略を選択できるようにお手伝いします。
ネストされたオブジェクト vs 外部キーリレーション
JOINの複雑さに深く踏み込む前に、少し視野を広げて「データの結合」というトピックが何を意味するのかを理解しましょう。
開発者であれば、おそらくネストされたオブジェクトの操作に慣れているでしょう。それらは次のように見えます。
この例では、「オブジェクト階層」は次のようになります: post → author → profile。
この種のネストされた構造は、オブジェクトの概念を持つほとんどのプログラミング言語でデータが表現される方法です。
しかし、以前にSQLデータベースを扱ったことがあれば、関連データはそこでは異なる方法、すなわち フラットな(または 正規化された)方法で表現されることをご存知でしょう。このアプローチでは、エンティティ間のリレーションは、テーブル間の 参照を指定する 外部キーを介して表現されます。
これら2つのアプローチの視覚的な表現です
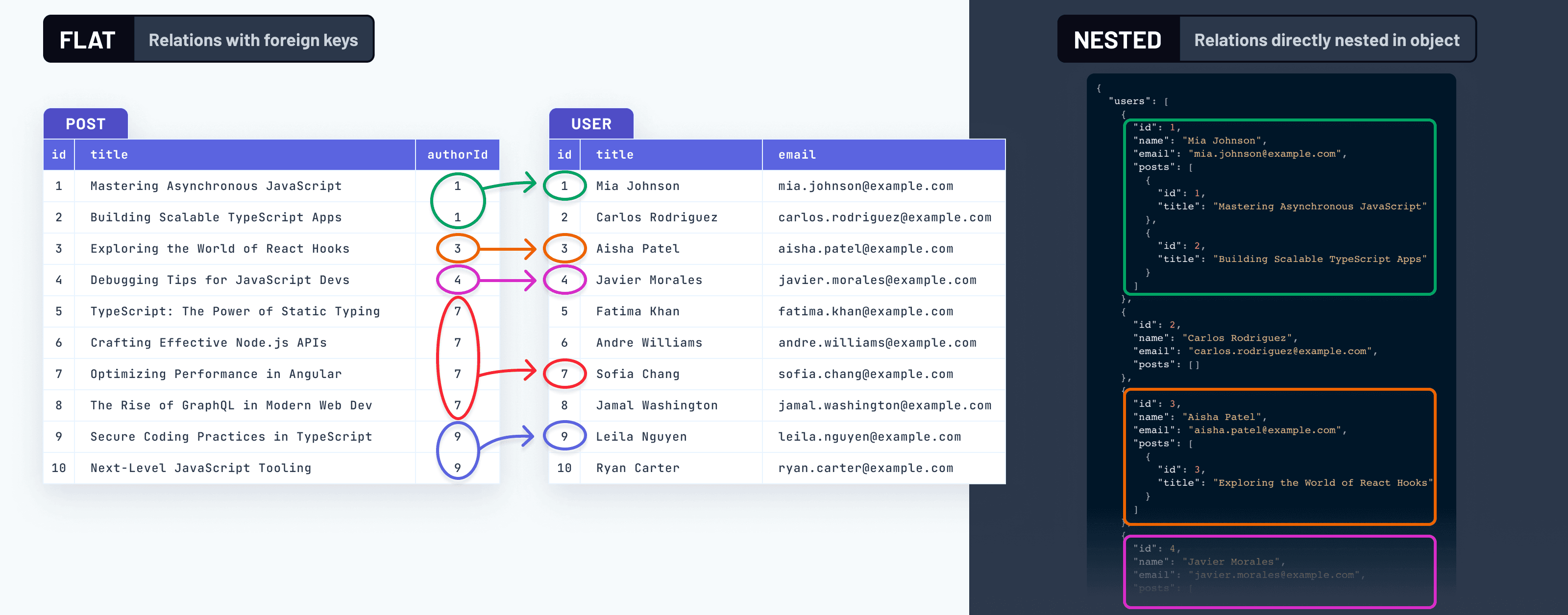
これは、データが 物理的に ディスク上およびメモリ上に配置される方法だけでなく、 メンタルモデルやデータについて推論する場合においても、大きな違いです。
「データの結合」とは何を意味しますか?
データの結合とは、SQLデータベースのフラットなレイアウトから、アプリケーション開発者がアプリケーションで利用できるネストされた構造にデータを変換するプロセスを指します。
これは次の2つの場所のいずれかで発生します
- データベース内: 単一のSQLクエリがデータベースに送信されます。このクエリは
JOINキーワード(または場合によっては相関サブクエリ)を使用して、データベースに複数のテーブル間で結合を実行させ、ネストされた構造を返します。この結合を行うには複数の方法があり、次のセクションで見ていきます。 - アプリケーション内: 複数のクエリがデータベースに送信されます。各クエリは単一のテーブルのみにアクセスし、クエリ結果はアプリケーション層で結合されます。
データベースレベルの結合には利点がありますが、複雑になりすぎるといくつかの欠点もあります。そのため、スキーマ、データセット、クエリの複雑さなどの要因に応じて、どちらかのアプローチが特定のユースケースにより適している場合があります。詳細については読み進めてください!
3つのJOIN戦略: 素朴な、スマートな、そしてアプリケーションレベルのJOIN
大まかに言えば、適用できる結合戦略には3つの異なる種類があります。「素朴な」DBレベルのJOINと「スマートな」DBレベルのJOIN、そして「アプリケーションレベル」のJOINです。以下のスキーマを使用して、これらを一つずつ見ていきましょう。
素朴なDBレベルJOINは冗長なデータにつながる
素朴なDBレベルJOINとは、最適化のための追加措置を講じないJOIN操作を指します。これらの種類のJOINは、いくつかの理由からパフォーマンスにとってしばしば悪影響を及ぼします。詳しく見ていきましょう!
例えば、開発者がusersテーブルとpostテーブルからデータを結合するために素朴に書くかもしれないシンプルなLEFT JOIN操作を次に示します。
データベースによって返される結果は次のようになるでしょう

何かに気づきましたか?user_name列のデータには多くの繰り返しがあります。
さて、クエリにcommentsを追加しましょう
これはさらに悪化しました!user_nameだけでなく、post_titleも繰り返されています。
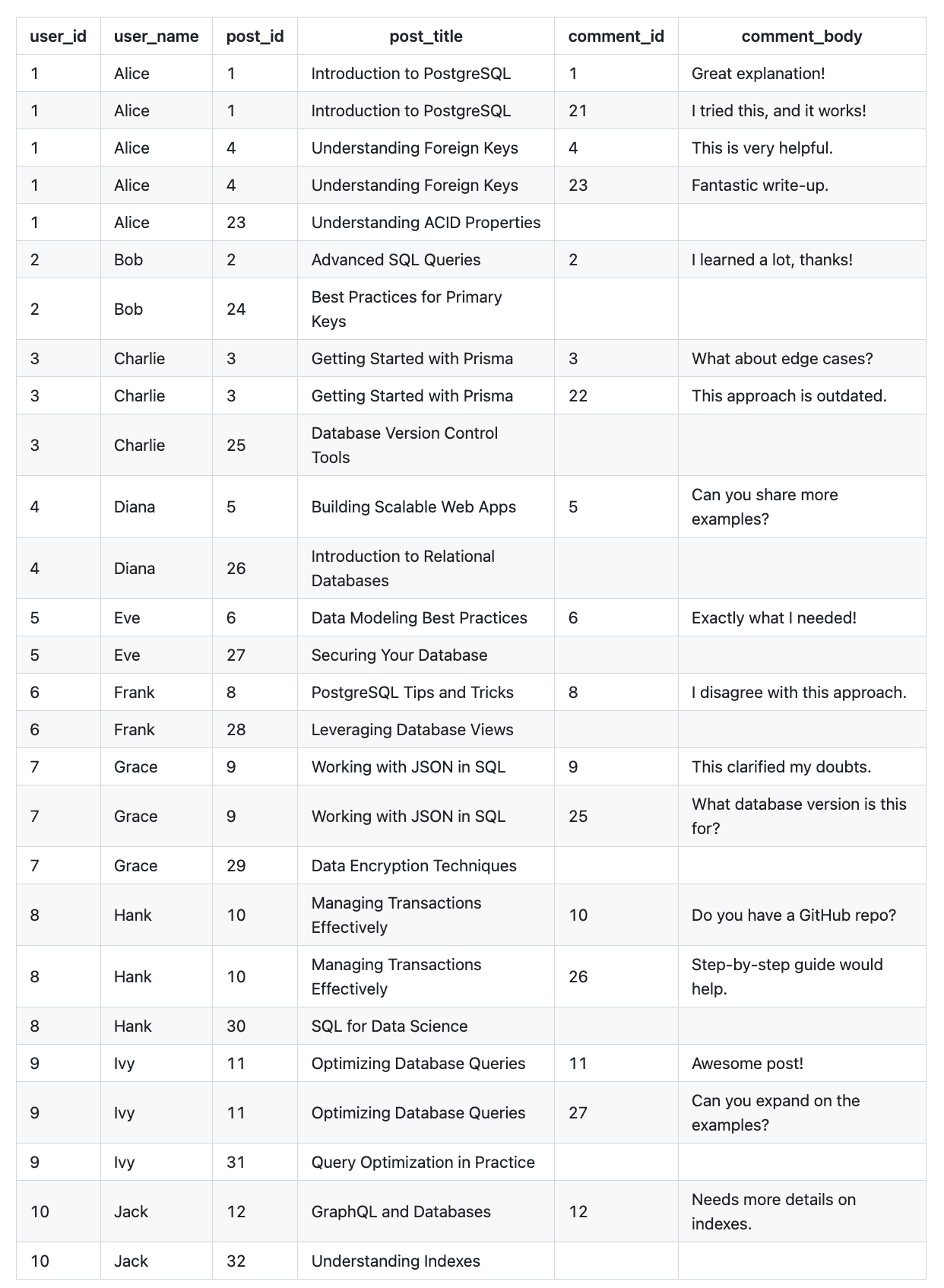
データの冗長性にはいくつかの負の側面があります
- ワイヤ上で送信される(不必要な)データ量が増加し、ネットワーク帯域幅を消費し、クエリ全体のレイテンシを増加させます。
- アプリケーション層は、望ましいネストされたオブジェクトに到達するために追加の作業を行う必要があります。
- 冗長なデータの重複を排除する
- データレコード間の関係を再構築する
さらに、この種の操作は、3つのテーブルすべてをクエリし、独自のインメモリマッピングを実行してデータを1つの結果セットに結合するため、データベースに高いCPUコストを発生させます。
上記はまだ比較的単純な例です。さらに多くのJOINとより深いネストでこれを行うことを想像してみてください。あるレベルを超えると、データベースはクエリプランの最適化を諦め、すべてのテーブルに対してテーブルスキャンを実行し、その後、独自のCPUを使用してメモリ内でデータを結合します。これはすぐにコストがかかります!
データベースのCPUとメモリは、アプリケーションレベルのCPUとメモリよりもスケーリングがはるかに複雑(かつ高コスト)です。したがって、状況を改善する一つの方法は、アプリケーションサーバーのCPUを使用してデータを結合する作業を行うことであり、これが次のアプローチ「アプリケーションレベルJOIN」につながります。
アプリケーションレベルJOINはシンプルで効率的ですが、ネットワークコストがかかります
これらの素朴なDBレベルJOINを行うもう一つの選択肢は、アプリケーション層でデータを結合することです。このシナリオでは、開発者は3つの異なるクエリを作成し、それらを個別にデータベースに送信します。データベースがクエリの結果を返した後、開発者は独自のビジネスロジックを適用してデータを自分で結合できます。
TypeScriptでは、その例は次のようになるでしょう(node-postgresのようなシンプルなPostgresドライバを使用した場合)。
このアプローチにはいくつかの利点があります
- データベースは、これらの各クエリに対して非常に最適な実行計画を生成し、単一のテーブルからデータを返すだけなので、事実上CPU作業を行いません。
- ワイヤ経由で送信されるデータは、アプリケーションのデータ要件に合わせて最適化されています(そして、素朴なDBレベルJOIN戦略のような冗長性の問題に悩まされることもありません)。
- マッピングと結合作業の大部分がアプリケーション自体で行われるようになったため、データベースサーバーはより複雑なクエリに対応するためのリソースを増やすことができます。
CPUコストをデータベースからアプリケーション層に移行することで、このアプローチはシステム全体の水平スケーラビリティを向上させます。
オライリーの書籍High Performance MySQLでは、このアプリケーションレベルの結合手法は結合分解と呼ばれています。「多くの高性能ウェブサイトでは 結合分解が使用されています。マルチテーブル結合の代わりに複数のシングルテーブルクエリを実行し、その後アプリケーションで結合を実行することで、結合を分解できます。」
しかし、大きな欠点は、データベースへの複数回の往復が必要となることです。アプリケーションサーバーとデータベースが互いに離れた場所に配置されている場合、これはパフォーマンスに深刻な影響を及ぼし、この戦略を実行不可能にする可能性のある重要な要因となります。ただし、データベースとアプリケーションが同じリージョンでホストされている場合、ネットワークオーバーヘッドはほとんど無視できるレベルであり、このアプローチが全体としてより高いパフォーマンスを発揮する可能性があります。
スマートなDBレベルJOINは冗長性の問題を解決する
素朴なDBレベルJOINは、データベースから関連データを取得する最良の方法とはほとんど言えません。しかし、だからといってデータベースがデータの結合を担当すべきではないということでしょうか?決してそうではありません!
データベースエンジンはここ数年で非常に強力になり、クエリを最適化する方法を常に改善してきました。データベースが最も最適なクエリプランを生成できるようにするためには、クエリの意図を理解できることが最も重要です。
これには2つの異なる要因があります
- JSON集約などの技術を使用して冗長性を削減する
- PostgreSQLの
LATERALJOIN(またはMySQLの相関サブクエリ)のような最新のデータベース機能を使用して、クエリの複雑さを軽減する
上記と同じスキーマの例を使用すると、これを表現する良い方法は次のとおりです。
このようなクエリは次の結果を生成します
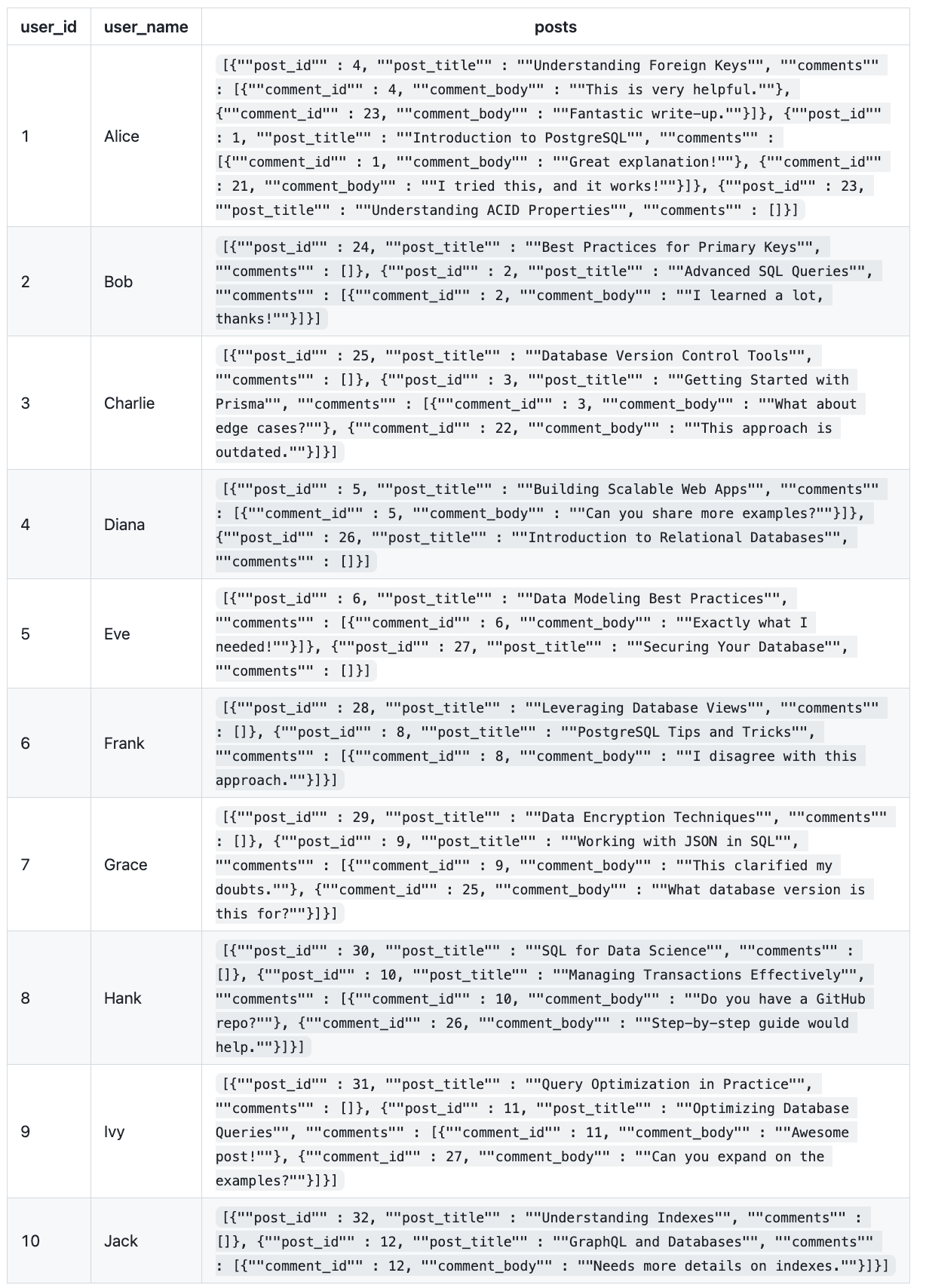
このデータは、素朴なDBレベルJOINのセクションからのデータに似ていますが、次の点が異なります。
- もはや冗長性を含んでいない
- 投稿はすでにJSON構造でフォーマットされている
このクエリは素朴な戦略よりも適切にフォーマットされた結果を生成するかもしれませんが、長く複雑にもなっています。ほとんどの実際のアプリケーションが扱っている追加の要因(例: フィルタリングやページネーション)なしで、3つのテーブルを結合するという比較的単純なシナリオについて話していることを忘れないでください。
Prisma ORMにおけるJOIN戦略の進化
Prisma ORMは2021年に最初にリリースされた際、そのすべてのリレーションクエリに対してアプリケーションレベルのJOIN戦略を実装していました。
この戦略は、アプリケーションサーバーとデータベースが互いに近くに配置されている場合に非常にうまく機能し、データベースエンジン間の移植性を高め、システム全体のスケーラビリティを向上させます(アプリケーション層のCPUはDBレベルのCPUよりも拡張が容易で安価であるため)。
アプリケーションレベルJOINのアプローチはほとんどの開発者にとって役立ってきましたが、アプリケーションサーバーとデータベースを互いに近くにホストできない場合があり、その追加の往復がクエリ全体のパフォーマンスに悪影響を与えるという問題を引き起こすことがありました。
そのため、1年前にスマートなDBレベルJOINを代替として追加し、開発者が個々のユースケースに最適な結合戦略を常に選択できるようにしました。
DBレベルJOINを使用できることは、Prisma ORMの最も人気のある機能リクエストの1つであり、プレビュー版でリリースされて以来、コミュニティから好評を得ています。この機能が一般提供されると、DBレベルJOINはPrisma ORMがリレーションクエリに適用するデフォルトの結合戦略になります。
コミュニティからのフィードバックは、Prisma ORMを改善するために取り組むべきことを優先順位付けする主要な要因の1つです。
結論
データベース内の複数のテーブルからデータを結合する最もパフォーマンスの高い方法を見つけることは複雑なトピックです。この記事では、DBレベルでの素朴なJOINとスマートなJOIN、そしてアプリケーションレベルのJOINという3つの異なるアプローチを検討しました。
素朴なDBレベルJOINは、データベースサーバーに高いCPUコストを発生させ、冗長なデータの不必要な転送によりネットワークオーバーヘッドを引き起こします。
アプリケーションレベルJOINは、そのシンプルさとデータベースレベルでの安価な実行により、多くのシナリオにより適している場合があります。この戦略を使用するシステムは、通常、拡張も容易でコストもかかりません。
最後に、スマートなDBレベルJOINは冗長性の問題を解決し、アプリケーション開発者のニーズに合わせてネストされた構造でデータを返すことができ、全体としてデータベースエンジンによってより最適化される可能性が高くなります。
次の投稿をお見逃しなく!
Prismaニュースレターに登録する