イントロスペクションとは?
Prisma CLIを使ってデータベースをイントロスペクトすることで、データモデルをPrisma スキーマ内に生成できます。データモデルはPrisma Clientを生成するために必要です。
イントロスペクションは、既存のプロジェクトにPrisma ORMを追加する際に、データモデルの初期バージョンを生成するためによく使用されます。
しかし、アプリケーションで繰り返し使用することも可能です。これは、Prisma Migrateを使用せず、プレーンなSQLや他のマイグレーションツールを使ってスキーママイグレーションを実行している場合に最も一般的です。その場合、データベースを再イントロスペクトし、その後Prisma Clientを再生成して、Prisma Client APIにスキーマ変更を反映させる必要があります。
イントロスペクションは何をするのですか?
イントロスペクションには一つの主要な機能があります。それは、現在のデータベーススキーマを反映したデータモデルでPrismaスキーマを生成することです。
SQLデータベースにおける主要機能の概要は以下の通りです。
- データベース内のテーブルをPrismaモデルにマッピングする
- データベース内の列をPrismaモデルのフィールドにマッピングする
- データベース内のインデックスをPrismaスキーマ内のインデックスにマッピングする
- データベース制約をPrismaスキーマ内の属性または型修飾子にマッピングする
MongoDBでは、主な機能は以下の通りです。
- データベース内のコレクションをPrismaモデルにマッピングします。MongoDBのコレクションは事前定義された構造を持たないため、Prisma ORMはコレクション内のドキュメントをサンプリングし、それに応じてモデル構造を導出します(つまり、ドキュメントのフィールドをPrismaモデルのフィールドにマッピングします)。コレクション内で埋め込み型が検出された場合、それらはPrismaスキーマの複合型にマッピングされます。
- コレクションにインデックスに含まれるフィールドを含むドキュメントが少なくとも1つ含まれている場合、データベースのインデックスをPrismaスキーマのインデックスにマッピングします。
Prisma ORMがデータベースの型をPrismaスキーマで利用可能な型にどのようにマッピングするかについては、各データソースコネクタのドキュメントページで詳しく学ぶことができます。
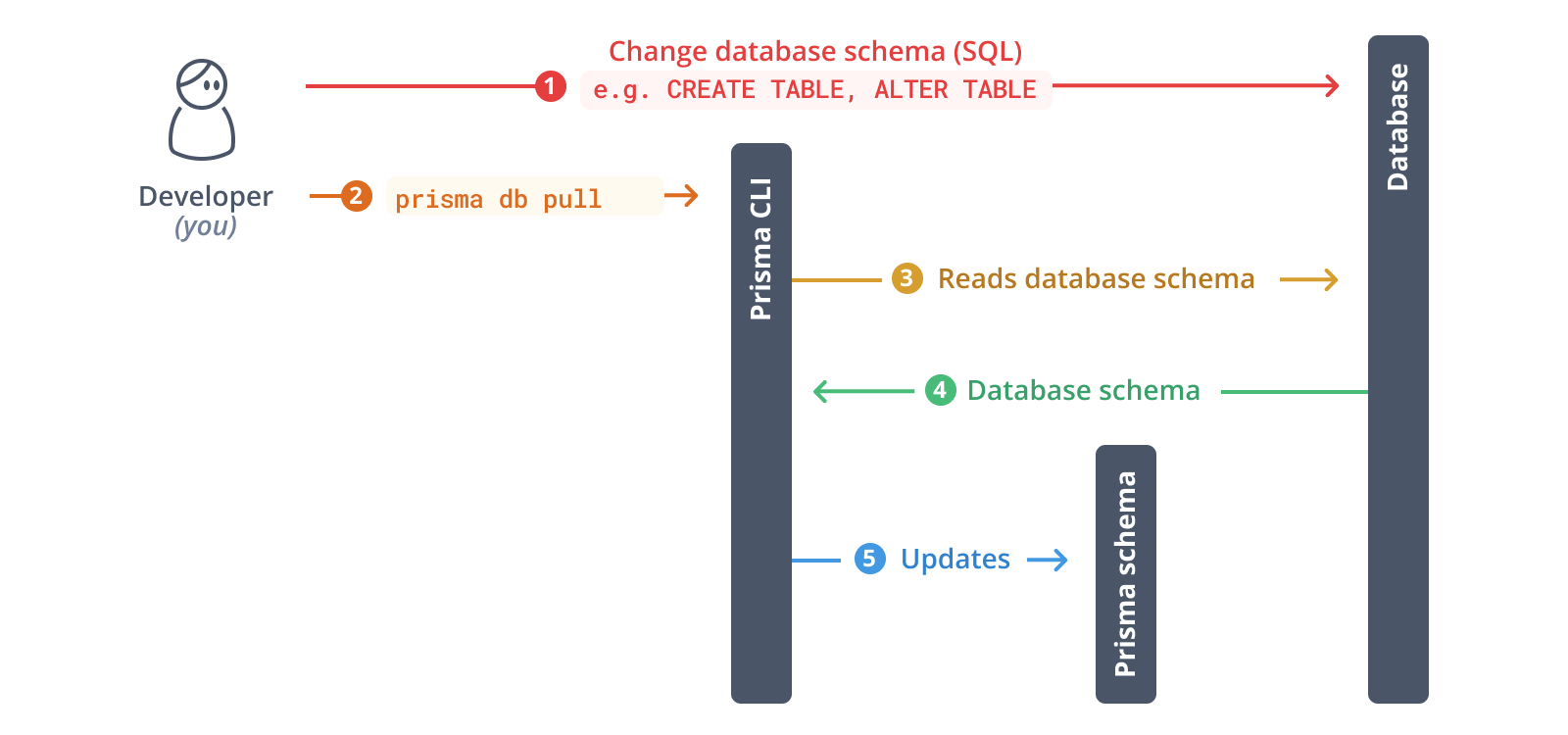
prisma db pullコマンド
Prisma CLIのprisma db pullコマンドを使用してデータベースをイントロスペクトできます。このコマンドを使用するには、Prismaスキーマのdatasourceに接続URLが設定されている必要があることに注意してください。
以下は、prisma db pullが内部的に実行する手順の概要です。
- Prismaスキーマの
datasource設定から接続URLを読み取る - データベースへの接続を開く
- データベーススキーマをイントロスペクトする(つまり、テーブル、カラム、その他の構造を読み取る…)
- データベーススキーマをPrismaスキーマデータモデルに変換する
- データモデルをPrismaスキーマに書き込むか、既存のスキーマを更新する
イントロスペクションワークフロー
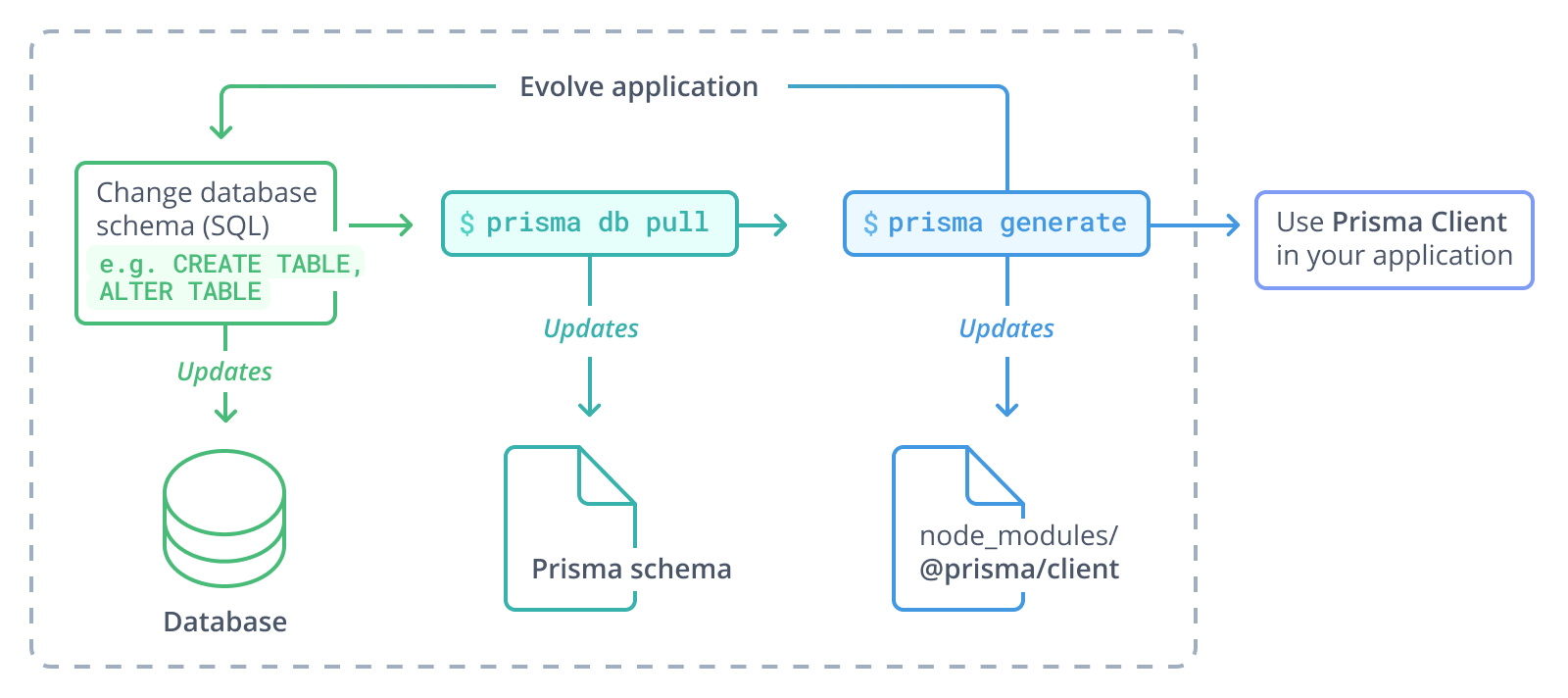
Prisma Migrateを使用せず、代わりにプレーンなSQLや他のマイグレーションツールを使用するプロジェクトの典型的なワークフローは以下のようになります。
- データベーススキーマを変更する(例:プレーンSQLを使用)
- Prismaスキーマを更新するために
prisma db pullを実行する - Prisma Clientを更新するために
prisma generateを実行する - 更新されたPrisma Clientをアプリケーションで使用する
アプリケーションを進化させるにつれて、このプロセスは何度でも繰り返すことができます。
ルールと規則
Prisma ORMは、データベーススキーマをPrismaスキーマのデータモデルに変換するために、いくつかの規則を採用しています。
モデル、フィールド、およびEnum名
フィールド、モデル、およびenumの名前(識別子)は文字で始まり、一般的にアンダースコア、文字、数字のみを含まなければなりません。これらの識別子ごとの命名規則と慣例は、各ドキュメントページで確認できます。
識別子に関する一般的なルールは、この正規表現に準拠する必要があるということです。
[A-Za-z][A-Za-z0-9_]*
無効な文字のサニタイズ
無効な文字はイントロスペクション中にサニタイズされます
- 識別子の文字の前に出現する場合、それらは削除されます。
- 最初の文字の後に出現する場合、それらはアンダースコアに置き換えられます。
さらに、変換された名前は@mapまたは@@mapを使用してデータベースにマッピングされ、元の名前が保持されます。
以下のテーブルを例に考えてみましょう。
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY,
_name VARCHAR(255),
two$two INTEGER
);
テーブル名の先頭の42や、カラムの先頭のアンダースコアと$はPrisma ORMで禁止されているため、イントロスペクションは@mapおよび@@map属性を追加し、これらの名前がPrisma ORMの命名規則に準拠するようにします。
model User {
id Int @id @default(autoincrement()) @map("_id")
name String? @map("_name")
two_two Int? @map("two$two")
@@map("42User")
}
サニタイズ後の重複する識別子
サニタイズの結果、識別子が重複しても、すぐにエラー処理は行われません。エラーは後で発生し、手動で修正できます。
以下の2つのテーブルのケースを考えてみましょう。
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY
);
CREATE TABLE "24User" (
_id SERIAL PRIMARY KEY
);
これは以下のイントロスペクション結果になります。
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("42User")
}
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("24User")
}
prisma generateでPrisma Clientを生成しようとすると、以下のエラーが発生します。
npx prisma generate
$ npx prisma generate
Error: Schema parsing
error: The model "User" cannot be defined because a model with that name already exists.
--> schema.prisma:17
|
16 | }
17 | model User {
|
Validation Error Count: 1
この場合、Prismaスキーマでは重複するモデル名が許可されていないため、生成された2つのUserモデルのいずれかの名前を手動で変更する必要があります。
フィールドの順序
イントロスペクションは、モデルのフィールドをデータベースの対応するテーブルの列と同じ順序でリストします。
属性の順序
イントロスペクションは以下の順序で属性を追加します(この順序はprisma formatによって反映されます)
- ブロックレベル:
@@id,@@unique,@@index,@@map - フィールドレベル:
@id,@unique,@default,@updatedAt,@map,@relation
リレーション
Prisma ORMは、データベーステーブルに定義されている外部キーをリレーションに変換します。
一対一リレーション
Prisma ORMは、テーブルの外部キーにUNIQUE制約がある場合、一対一リレーションをデータモデルに追加します。例:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Profile" (
id SERIAL PRIMARY KEY,
"user" integer NOT NULL UNIQUE,
FOREIGN KEY ("user") REFERENCES "User"(id)
);
Prisma ORMはこれを以下のデータモデルに変換します。
model User {
id Int @id @default(autoincrement())
Profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user Int @unique
User User @relation(fields: [user], references: [id])
}
一対多リレーション
デフォルトでは、Prisma ORMはデータベーススキーマで見つかった外部キーに対して、データモデルに一対多リレーションを追加します。
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
FOREIGN KEY ("author") REFERENCES "User"(id)
);
これらのテーブルは以下のモデルに変換されます。
model User {
id Int @id @default(autoincrement())
Post Post[]
}
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
多対多リレーション
多対多リレーションは、リレーショナルデータベースでは一般的にリレーションテーブルとして表現されます。
Prisma ORMは、Prismaスキーマで多対多リレーションを定義するための2つの方法をサポートしています。
- 暗黙的な多対多リレーション(Prisma ORMがリレーションテーブルを内部で管理します)
- 明示的な多対多リレーション(リレーションテーブルがモデルとして存在します)
暗黙的な多対多リレーションは、Prisma ORMのリレーションテーブルの規則に準拠している場合に認識されます。そうでなければ、リレーションテーブルはPrismaスキーマにモデルとしてレンダリングされます(そのため、明示的な多対多リレーションとなります)。
このトピックは、リレーションに関するドキュメントページで詳しく説明されています。
リレーションの明確化
Prisma ORMは一般的に、必要ない場合、@relation属性のname引数を省略します。前のセクションのUser ↔ Postの例を考えてみましょう。@relation属性にはreferences引数のみがあり、nameはこの場合必要ないため省略されています。
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
Postテーブルに2つの外部キーが定義されている場合は必要になります。
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
"favoritedBy" INTEGER,
FOREIGN KEY ("author") REFERENCES "User"(id),
FOREIGN KEY ("favoritedBy") REFERENCES "User"(id)
);
この場合、Prisma ORMは専用のリレーション名を使用してリレーションを明確化する必要があります。
model Post {
id Int @id @default(autoincrement())
author Int
favoritedBy Int?
User_Post_authorToUser User @relation("Post_authorToUser", fields: [author], references: [id])
User_Post_favoritedByToUser User? @relation("Post_favoritedByToUser", fields: [favoritedBy], references: [id])
}
model User {
id Int @id @default(autoincrement())
Post_Post_authorToUser Post[] @relation("Post_authorToUser")
Post_Post_favoritedByToUser Post[] @relation("Post_favoritedByToUser")
}
生成されたPrisma Client APIでより分かりやすくなるように、Prisma-ORMレベルのリレーションフィールドは自由に名前変更できることに注意してください。
既存のスキーマでのイントロスペクション
既存のPrismaスキーマを持つリレーショナルデータベースに対してprisma db pullを実行すると、スキーマに手動で加えられた変更とデータベースで行われた変更がマージされます。(この機能はバージョン2.6.0で初めて追加されました。)MongoDBの場合、イントロスペクションは今のところ最初のデータモデルに対してのみ実行されることを意図しています。繰り返し実行すると、以下に挙げるようなカスタム変更が失われる可能性があります。
リレーショナルデータベースのイントロスペクションは、以下の手動変更を維持します。
modelブロックの順序enumブロックの順序- コメント
@mapおよび@@map属性@updatedAt@default(cuid())(cuid()はPrisma-ORMレベルの関数)@default(uuid())(uuid()はPrisma-ORMレベルの関数)- カスタム
@relation名
注:モデル間のデータベースレベルのリレーションのみが検出されます。つまり、外部キーが設定されている必要があります。
スキーマの以下のプロパティはデータベースによって決定されます。
modelブロック内のフィールドの順序enumブロック内の値の順序
注: すべての
enumブロックはmodelブロックの下にリストされます。
強制上書き
手動による変更を上書きし、既存のPrismaスキーマを無視して、イントロスペクトされたデータベースに基づいてのみスキーマを生成するには、db pullコマンドに--forceフラグを追加します。
npx prisma db pull --force
使用例は以下の通りです。
- 基盤となるデータベースから生成されたスキーマで最初から始めたい場合
- 無効なスキーマがあり、イントロスペクションを成功させるために
--forceを使用する必要がある場合
データベーススキーマの一部分のみをイントロスペクトする
データベーススキーマの一部分のみをイントロスペクトすることは、Prisma ORMではまだ公式にはサポートされていません。
ただし、Prismaスキーマに表現したいテーブルにのみアクセス権を持つ新しいデータベースユーザーを作成し、そのユーザーを使用してイントロスペクションを実行することで、これを実現できます。イントロスペクションには、新しいユーザーがアクセスできるテーブルのみが含まれます。
Prisma Client生成から特定のモデルを除外することが目標であれば、Prismaスキーマのモデル定義に@@ignore属性を追加できます。無視されたモデルは、生成されるPrisma Clientから除外されます。
サポートされていない機能に関するイントロスペクション警告
Prismaスキーマ言語(PSL)は、Prisma ORMがサポートする対象データベースのほとんどのデータベース機能を表現できます。しかし、Prismaスキーマ言語がまだ表現する必要がある機能や機能性があります。
これらの機能については、Prisma CLIはデータベースでのその機能の使用を検出し、警告を返します。Prisma CLIは、その機能がPrismaスキーマで使用されているモデルやフィールドにコメントも追加します。警告には回避策の提案も含まれます。
prisma db pullコマンドは、以下のサポートされていない機能を通知します。
サポートを予定している機能のリストはGitHub(topic:database-functionalityでラベル付けされています)で確認できます。
サポートされていない機能に関するイントロスペクション警告の回避策
リレーショナルデータベースを使用しており、前のセクションに記載されているいずれかの機能を使用している場合
- ドラフトマイグレーションを作成する
npx prisma migrate dev --create-only - 警告で示された機能を追加するSQLを追加します。
- ドラフトマイグレーションをデータベースに適用する
npx prisma migrate dev