JavaScript プロジェクトにおける MySQL のイントロスペクション
Prisma ORM でデータベースをイントロスペクトする
このガイドでは、3つのテーブルを持つデモ用SQLスキーマを使用します
CREATE TABLE User (
id INTEGER PRIMARY KEY AUTO_INCREMENT NOT NULL,
name VARCHAR(255),
email VARCHAR(255) UNIQUE NOT NULL
);
CREATE TABLE Post (
id INTEGER PRIMARY KEY AUTO_INCREMENT NOT NULL,
title VARCHAR(255) NOT NULL,
createdAt TIMESTAMP NOT NULL DEFAULT now(),
content TEXT,
published BOOLEAN NOT NULL DEFAULT false,
authorId INTEGER NOT NULL,
FOREIGN KEY (authorId) REFERENCES User(id)
);
CREATE TABLE Profile (
id INTEGER PRIMARY KEY AUTO_INCREMENT NOT NULL,
bio TEXT,
userId INTEGER UNIQUE NOT NULL,
FOREIGN KEY (userId) REFERENCES User(id)
);
テーブルのグラフィカルな概要を展開
User
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INTEGER | ✔️ | いいえ | ✔️ | 自動インクリメント |
name | VARCHAR(255) | いいえ | いいえ | いいえ | - |
email | VARCHAR(255) | いいえ | いいえ | ✔️ | - |
Post
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INTEGER | ✔️ | いいえ | ✔️ | 自動インクリメント |
createdAt | DATETIME(3) | いいえ | いいえ | ✔️ | now() |
title | VARCHAR(255) | いいえ | いいえ | ✔️ | - |
content | TEXT | いいえ | いいえ | いいえ | - |
published | BOOLEAN | いいえ | いいえ | ✔️ | false |
authorId | INTEGER | いいえ | ✔️ | ✔️ | false |
Profile
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INTEGER | ✔️ | いいえ | ✔️ | 自動インクリメント |
bio | TEXT | いいえ | いいえ | いいえ | - |
userId | INTEGER | いいえ | ✔️ | ✔️ | - |
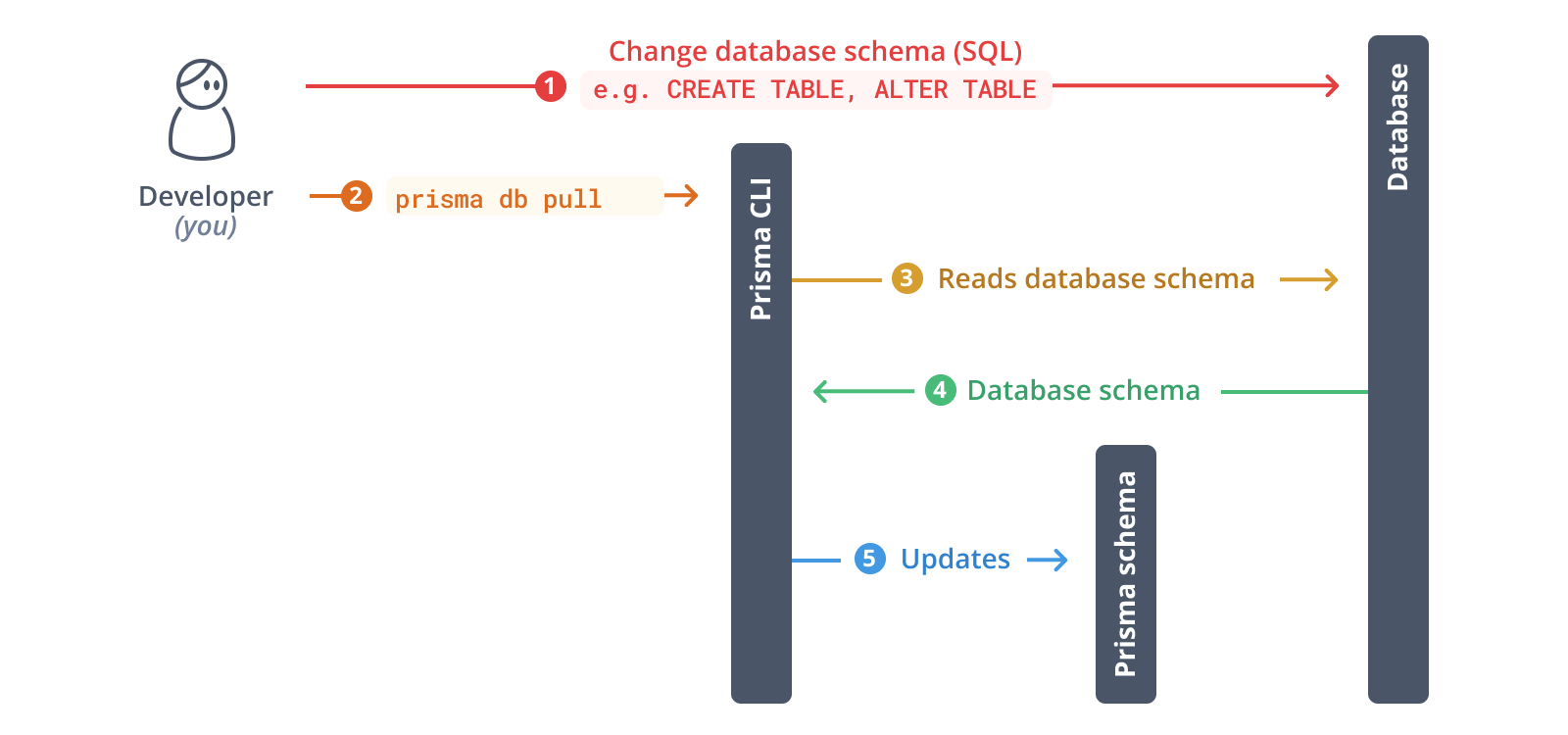
次のステップとして、データベースをイントロスペクトします。イントロスペクションの結果は、Prisma スキーマ内にデータモデルとして生成されます。
データベースをイントロスペクトするために以下のコマンドを実行します
npx prisma db pull
このコマンドは、.envで定義されているDATABASE_URL環境変数を読み込み、データベースに接続します。接続が確立されると、データベースをイントロスペクトします(つまり、データベーススキーマを読み取ります)。その後、データベーススキーマをSQLからPrismaデータモデルに変換します。
イントロスペクションが完了すると、Prisma スキーマが更新されます
データモデルは次のようになります(モデルのフィールドは読みやすさのために並べ替えられています)
model Post {
id Int @id @default(autoincrement())
title String @db.VarChar(255)
createdAt DateTime @default(now()) @db.Timestamp(0)
content String? @db.Text
published Boolean @default(false)
authorId Int
User User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction, map: "Post_ibfk_1")
@@index([authorId], map: "authorId")
}
model Profile {
id Int @id @default(autoincrement())
bio String? @db.Text
userId Int @unique(map: "userId")
User User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction, map: "Profile_ibfk_1")
}
model User {
id Int @id @default(autoincrement())
name String? @db.VarChar(255)
email String @unique(map: "email") @db.VarChar(255)
Post Post[]
Profile Profile?
}
スキーマ定義の詳細については、Prisma スキーマリファレンスを参照してください。
Prisma ORM のデータモデルは、データベーススキーマを宣言的に表現したものであり、生成される Prisma Client ライブラリの基盤となります。Prisma Client インスタンスは、これらのモデルに合わせたクエリを公開します。
現時点では、データモデルにいくつかの軽微な「問題」があります
Userリレーションフィールドは大文字で記述されており、Prisma の命名規則に従っていません。より「意味」を表現するために、このフィールドをauthorとすることで、UserとPost間の関係をよりよく記述できると良いでしょう。UserのPostおよびProfileリレーションフィールド、ならびにProfileのUserリレーションフィールドはすべて大文字で記述されています。Prisma の命名規則に従うためには、両方のフィールドを小文字のpost、profile、userにする必要があります。- 小文字にした後でも、
Userのpostフィールドはわずかに間違った名前です。これは、実際には投稿のリストを参照しているためです。したがって、より良い名前は複数形のpostsとなります。
これらの変更は、小文字のリレーションフィールドauthor、posts、profile、userを使用することで、JavaScript/TypeScript 開発者にとってより自然で慣用的なものとなる、生成される Prisma Client API に関係します。したがって、Prisma Client API を設定できます。
Because リレーションフィールドは仮想的である(つまり、データベースに直接現れない)ため、データベースに触れることなく、Prisma スキーマで手動で名前を変更できます
model Post {
id Int @id @default(autoincrement())
title String @db.VarChar(255)
createdAt DateTime @default(now()) @db.Timestamp(0)
content String? @db.Text
published Boolean @default(false)
authorId Int
author User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction, map: "Post_ibfk_1")
@@index([authorId], map: "authorId")
}
model Profile {
id Int @id @default(autoincrement())
bio String? @db.Text
userId Int @unique(map: "userId")
user User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction, map: "Profile_ibfk_1")
}
model User {
id Int @id @default(autoincrement())
name String? @db.VarChar(255)
email String @unique(map: "email") @db.VarChar(255)
posts Post[]
profile Profile?
}
この例では、データベーススキーマは Prisma ORM モデルの命名規則に従っていました(イントロスペクションから生成された仮想リレーションフィールドのみがそれに従わず、調整が必要でした)。これにより、生成される Prisma Client API のエルゴノミクスが最適化されます。
ただし、Prisma Client API で公開されるカラムやテーブルの名前に、追加の変更を加えたい場合があります。一般的な例としては、データベーススキーマでよく使用されるsnake_case表記を、JavaScript/TypeScript 開発者にとってより自然なPascalCaseおよびcamelCase表記に変換することです。
snake_case表記に基づいた、イントロスペクションから以下のモデルを取得したと仮定します
model my_user {
user_id Int @id @default(autoincrement())
first_name String?
last_name String @unique
}
このモデルに対して Prisma Client API を生成した場合、API ではsnake_case表記が採用されます
const user = await prisma.my_user.create({
data: {
first_name: 'Alice',
last_name: 'Smith',
},
})
Prisma Client API でデータベースのテーブル名やカラム名を使用しない場合は、@map と @@mapで設定できます
model MyUser {
userId Int @id @default(autoincrement()) @map("user_id")
firstName String? @map("first_name")
lastName String @unique @map("last_name")
@@map("my_user")
}
このアプローチでは、モデルとそのフィールドに好きな名前を付け、@map(フィールド名用)および@@map(モデル名用)を使用して、基になるテーブルとカラムを指すことができます。Prisma Client API は次のようになります
const user = await prisma.myUser.create({
data: {
firstName: 'Alice',
lastName: 'Smith',
},
})
詳細については、Prisma Client API の設定ページを参照してください。