JavaScriptプロジェクトにおけるPostgreSQLのイントロスペクション
Prisma ORMでデータベースをイントロスペクト
このガイドでは、3つのテーブルを持つデモ用SQLスキーマを使用します
CREATE TABLE "public"."User" (
id SERIAL PRIMARY KEY NOT NULL,
name VARCHAR(255),
email VARCHAR(255) UNIQUE NOT NULL
);
CREATE TABLE "public"."Post" (
id SERIAL PRIMARY KEY NOT NULL,
title VARCHAR(255) NOT NULL,
"createdAt" TIMESTAMP NOT NULL DEFAULT now(),
content TEXT,
published BOOLEAN NOT NULL DEFAULT false,
"authorId" INTEGER NOT NULL,
FOREIGN KEY ("authorId") REFERENCES "public"."User"(id)
);
CREATE TABLE "public"."Profile" (
id SERIAL PRIMARY KEY NOT NULL,
bio TEXT,
"userId" INTEGER UNIQUE NOT NULL,
FOREIGN KEY ("userId") REFERENCES "public"."User"(id)
);
注意:PostgreSQLで適切な大文字小文字を確実に使用するために、一部のフィールドは二重引用符で囲まれています。二重引用符を使用しない場合、PostgreSQLはすべてを小文字として読み取ります。
テーブルのグラフィカルな概要を展開
User
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | SERIAL | ✔️ | いいえ | ✔️ | 自動インクリメント |
name | VARCHAR(255) | いいえ | いいえ | いいえ | - |
email | VARCHAR(255) | いいえ | いいえ | ✔️ | - |
Post
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | SERIAL | ✔️ | いいえ | ✔️ | 自動インクリメント |
createdAt | TIMESTAMP | いいえ | いいえ | ✔️ | now() |
title | VARCHAR(255) | いいえ | いいえ | ✔️ | - |
content | TEXT | いいえ | いいえ | いいえ | - |
published | BOOLEAN | いいえ | いいえ | ✔️ | false |
authorId | INTEGER | いいえ | ✔️ | ✔️ | - |
Profile
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | SERIAL | ✔️ | いいえ | ✔️ | 自動インクリメント |
bio | TEXT | いいえ | いいえ | いいえ | - |
userId | INTEGER | いいえ | ✔️ | ✔️ | - |
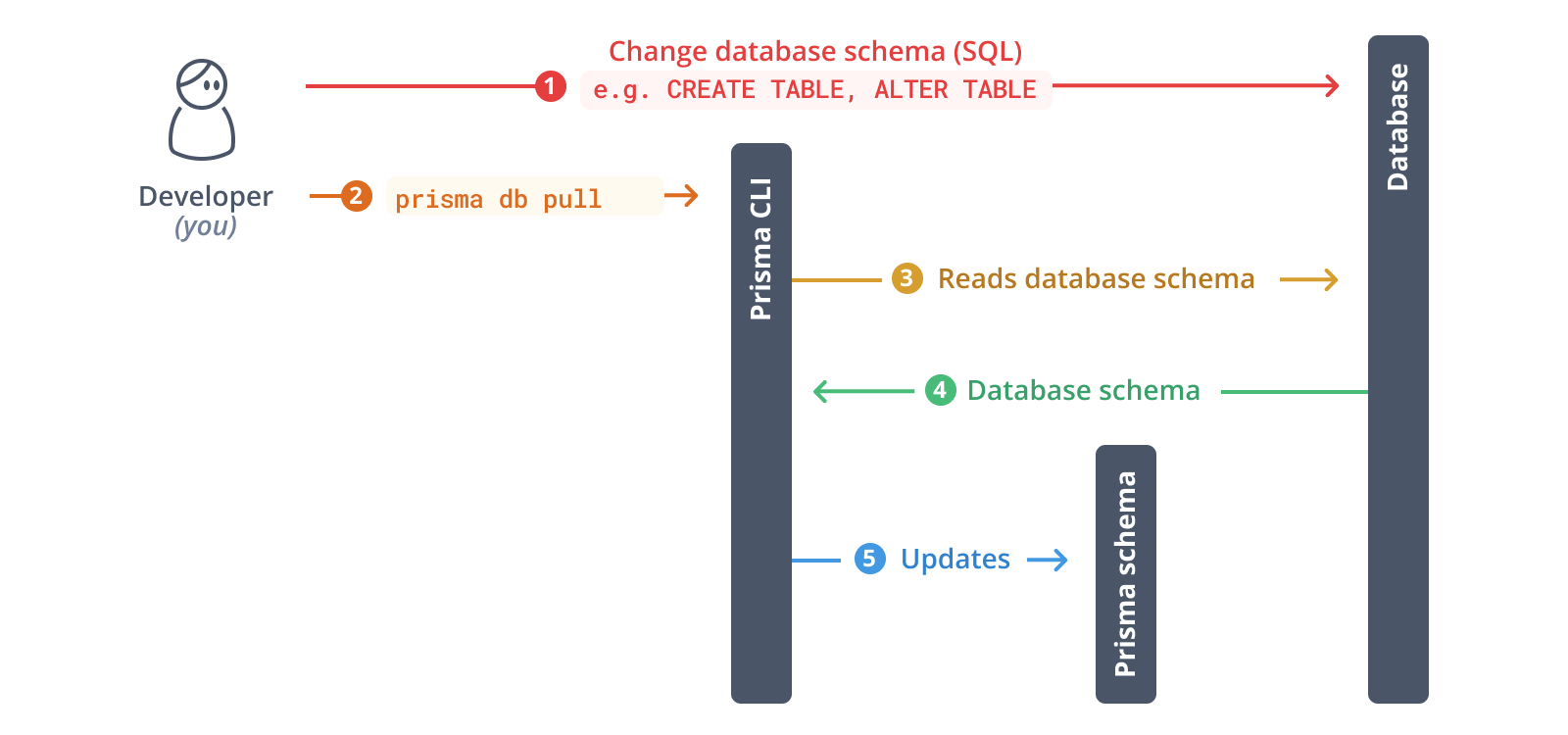
次のステップとして、データベースをイントロスペクトします。イントロスペクションの結果は、Prismaスキーマ内のデータモデルになります。
データベースをイントロスペクトするには、以下のコマンドを実行します
npx prisma db pull
このコマンドは、`.env`で定義されている`DATABASE_URL`環境変数を読み取り、データベースに接続します。接続が確立されると、データベースをイントロスペクトし(つまり、データベーススキーマを読み取り)、SQLのデータベーススキーマをPrismaスキーマのデータモデルに変換します。
イントロスペクションが完了すると、Prismaスキーマが更新されます
データモデルは以下のようになります(モデルのフィールドは読みやすさのために並べ替えられています)
model Post {
id Int @id @default(autoincrement())
title String @db.VarChar(255)
createdAt DateTime @default(now()) @db.Timestamp(6)
content String?
published Boolean @default(false)
authorId Int
User User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model Profile {
id Int @id @default(autoincrement())
bio String?
userId Int @unique
User User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model User {
id Int @id @default(autoincrement())
name String? @db.VarChar(255)
email String @unique @db.VarChar(255)
Post Post[]
Profile Profile?
}
Prisma ORMのデータモデルは、データベーススキーマを宣言的に表現したものであり、生成されるPrisma Clientライブラリの基盤となります。Prisma Clientインスタンスは、これらのモデルに特化したクエリを公開します。
現在、データモデルにはいくつかの小さな「問題」があります
- `User`リレーションフィールドが大文字になっており、Prismaの命名規則に準拠していません。より「セマンティクス」を表現するために、このフィールドを`author`と呼ぶことで、`User`と`Post`間の関係をより適切に記述できれば良いでしょう。
- `User`の`Post`と`Profile`リレーションフィールド、および`Profile`の`User`リレーションフィールドはすべて大文字になっています。Prismaの命名規則に準拠するためには、両方のフィールドを`post`、`profile`、`user`と小文字にする必要があります。
- 小文字にした後でも、`User`の`post`フィールドはわずかに誤った名前です。これは、実際には投稿のリストを参照しているため、より良い名前は複数形の`posts`になります。
これらの変更は、生成されるPrisma Client APIに関連しており、小文字のリレーションフィールド`author`、`posts`、`profile`、`user`を使用することで、JavaScript/TypeScript開発者にとってより自然で慣用的なものになります。したがって、Prisma Client APIを設定することができます。
リレーションフィールドは仮想的である(つまり、データベースに直接は現れない)ため、データベースに手を加えることなくPrismaスキーマで手動で名前を変更できます
model Post {
id Int @id @default(autoincrement())
title String @db.VarChar(255)
createdAt DateTime @default(now()) @db.Timestamp(6)
content String?
published Boolean @default(false)
authorId Int
author User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model Profile {
id Int @id @default(autoincrement())
bio String?
userId Int @unique
user User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model User {
id Int @id @default(autoincrement())
name String? @db.VarChar(255)
email String @unique @db.VarChar(255)
posts Post[]
profile Profile?
}
この例では、データベーススキーマはPrisma ORMモデルの命名規則に従っていました(イントロスペクションから生成された仮想リレーションフィールドのみがそれらに準拠しておらず、調整が必要でした)。これにより、生成されたPrisma Client APIのエルゴノミクスが最適化されます。
カスタムモデル名とフィールド名の使用
ただし、Prisma Client APIで公開されるカラム名やテーブル名に追加の変更を加えたい場合があります。一般的な例としては、データベーススキーマでよく使用されるsnake_case表記を、JavaScript/TypeScript開発者にとってより自然なPascalCaseやcamelCase表記に変換することが挙げられます。
イントロスペクションから、snake_case表記に基づいた以下のモデルが得られたとします
model my_user {
user_id Int @id @default(autoincrement())
first_name String?
last_name String @unique
}
このモデルに対してPrisma Client APIを生成した場合、そのAPIはsnake_case表記を使用します
const user = await prisma.my_user.create({
data: {
first_name: 'Alice',
last_name: 'Smith',
},
})
Prisma Client APIでデータベースのテーブル名やカラム名を使用しない場合、@mapと@@mapを使用して設定できます
model MyUser {
userId Int @id @default(autoincrement()) @map("user_id")
firstName String? @map("first_name")
lastName String @unique @map("last_name")
@@map("my_user")
}
このアプローチにより、モデルとそのフィールドを好きなように命名し、`@map`(フィールド名用)と`@@map`(モデル名用)を使用して基になるテーブルやカラムを指すことができます。Prisma Client APIは以下のようになります
const user = await prisma.myUser.create({
data: {
firstName: 'Alice',
lastName: 'Smith',
},
})
詳細については、Prisma Client APIの設定ページを参照してください。