TypeScriptプロジェクトにおけるCockroachDBのイントロスペクション
Prisma ORMでデータベースをイントロスペクトする
このガイドでは、3つのテーブルを持つデモSQLスキーマを使用します
CREATE TABLE "User" (
id INT8 PRIMARY KEY DEFAULT unique_rowid(),
name STRING(255),
email STRING(255) UNIQUE NOT NULL
);
CREATE TABLE "Post" (
id INT8 PRIMARY KEY DEFAULT unique_rowid(),
title STRING(255) UNIQUE NOT NULL,
"createdAt" TIMESTAMP NOT NULL DEFAULT now(),
content STRING,
published BOOLEAN NOT NULL DEFAULT false,
"authorId" INT8 NOT NULL,
FOREIGN KEY ("authorId") REFERENCES "User"(id)
);
CREATE TABLE "Profile" (
id INT8 PRIMARY KEY DEFAULT unique_rowid(),
bio STRING,
"userId" INT8 UNIQUE NOT NULL,
FOREIGN KEY ("userId") REFERENCES "User"(id)
);
注意: CockroachDBが適切な大文字・小文字を区別するように、一部のフィールドは二重引用符で囲まれています。二重引用符を使用しない場合、CockroachDBはすべてを小文字として読み取ります。
テーブルのグラフィカルな概要を展開
ユーザー
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INT8 | ✔️ | いいえ | ✔️ | 自動インクリメント |
name | STRING(255) | いいえ | いいえ | いいえ | - |
email | STRING(255) | いいえ | いいえ | ✔️ | - |
投稿
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INT8 | ✔️ | いいえ | ✔️ | 自動インクリメント |
createdAt | TIMESTAMP | いいえ | いいえ | ✔️ | now() |
title | STRING(255) | いいえ | いいえ | ✔️ | - |
content | STRING | いいえ | いいえ | いいえ | - |
published | BOOLEAN | いいえ | いいえ | ✔️ | false |
authorId | INT8 | いいえ | ✔️ | ✔️ | - |
プロフィール
| カラム名 | 型 | 主キー | 外部キー | 必須 | デフォルト |
|---|---|---|---|---|---|
id | INT8 | ✔️ | いいえ | ✔️ | 自動インクリメント |
bio | STRING | いいえ | いいえ | いいえ | - |
userId | INT8 | いいえ | ✔️ | ✔️ | - |
次のステップとして、データベースをイントロスペクトします。イントロスペクションの結果は、Prismaスキーマ内のデータモデルになります。
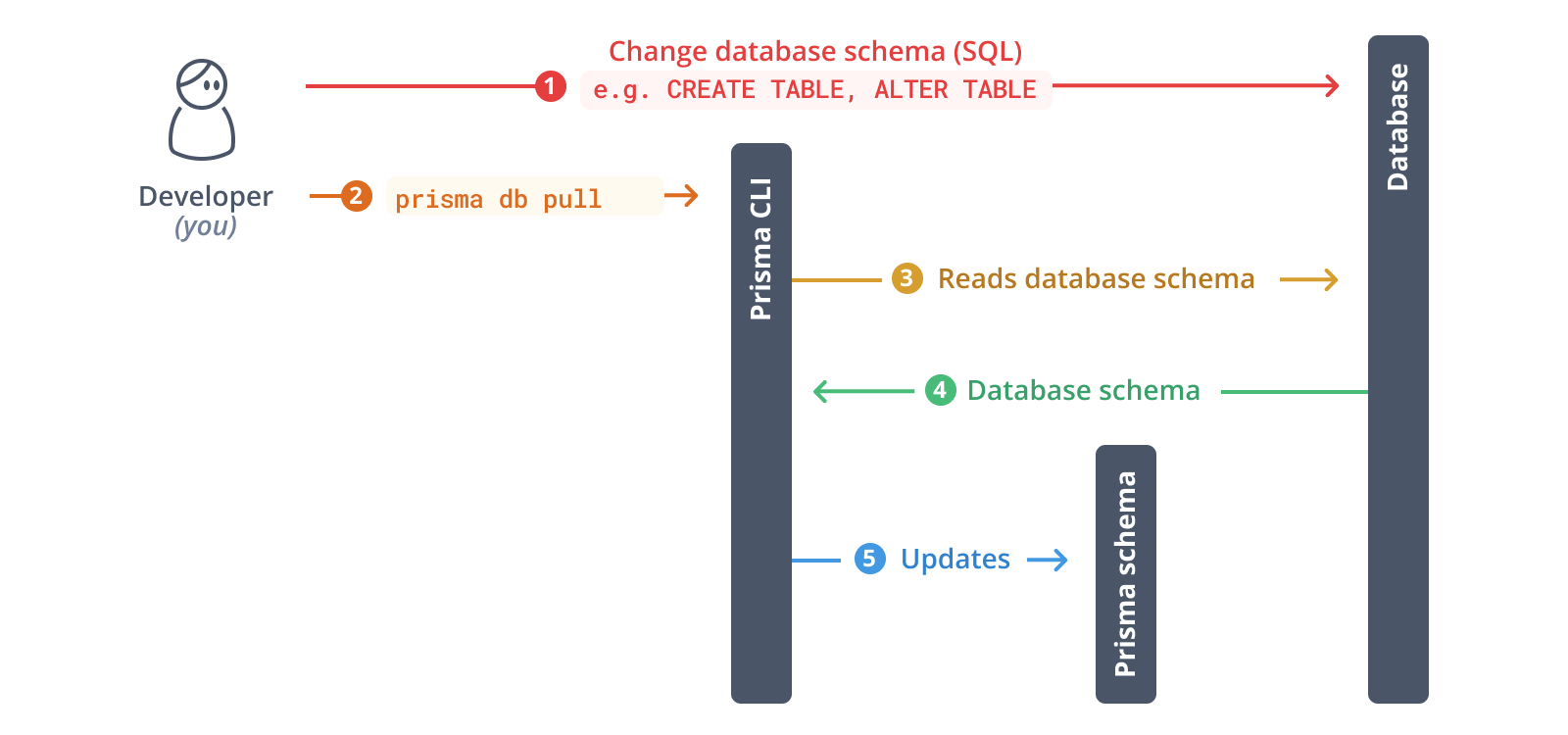
データベースをイントロスペクトするには、次のコマンドを実行します
npx prisma db pull
このコマンドは、`schema.prisma`で`url`を定義するために使用される環境変数`DATABASE_URL`(この場合は`.env`に設定されています)を読み取り、データベースに接続します。接続が確立されると、データベースをイントロスペクトし(つまり、データベーススキーマを読み取り)、SQLのデータベーススキーマをPrismaデータモデルに変換します。
イントロスペクションが完了すると、Prismaスキーマが更新されます
データモデルは次のようになります
model Post {
id BigInt @id @default(autoincrement())
title String @unique @db.String(255)
createdAt DateTime @default(now()) @db.Timestamp(6)
content String?
published Boolean @default(false)
authorId BigInt
User User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model Profile {
id BigInt @id @default(autoincrement())
bio String?
userId BigInt @unique
User User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model User {
id BigInt @id @default(autoincrement())
name String? @db.String(255)
email String @unique @db.String(255)
Post Post[]
Profile Profile?
}
Prisma ORMのデータモデルは、データベーススキーマの宣言的な表現であり、生成されるPrisma Clientライブラリの基盤となります。Prisma Clientインスタンスは、これらのモデルに合わせたクエリを公開します。
現在、データモデルにはいくつかの小さな「問題」があります
- `User`リレーションフィールドが大文字になっており、Prismaの命名規則に準拠していません。より「意味」を表現するために、このフィールドを`author`と呼んで`User`と`Post`間の関係をよりよく記述できれば、さらに良いでしょう。
- `User`上の`Post`および`Profile`リレーションフィールド、ならびに`Profile`上の`User`リレーションフィールドはすべて大文字になっています。Prismaの命名規則に準拠するには、両方のフィールドを`post`、`profile`、`user`のように小文字にする必要があります。
- 小文字にした後でも、`User`上の`post`フィールドは少し名前が間違っています。これは実際には投稿のリストを参照しているため、より良い名前は複数形である`posts`でしょう。
これらの変更は、生成されたPrisma Client APIにおいて、小文字のリレーションフィールド`author`、`posts`、`profile`、`user`を使用する方がJavaScript/TypeScript開発者にとってより自然で慣用的なものに感じられるため、重要です。そのため、Prisma Client APIを構成できます。
リレーションフィールドは仮想的(つまり、データベースに直接現れない)であるため、データベースに手を加えることなくPrismaスキーマ内で手動で名前を変更できます
model Post {
id BigInt @id @default(autoincrement())
title String @unique @db.String(255)
createdAt DateTime @default(now()) @db.Timestamp(6)
content String?
published Boolean @default(false)
authorId BigInt
author User @relation(fields: [authorId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model Profile {
id BigInt @id @default(autoincrement())
bio String?
userId BigInt @unique
user User @relation(fields: [userId], references: [id], onDelete: NoAction, onUpdate: NoAction)
}
model User {
id BigInt @id @default(autoincrement())
name String? @db.String(255)
email String @unique @db.String(255)
posts Post[]
profile Profile?
}
この例では、データベーススキーマはPrisma ORMモデルの命名規則に従っていました(イントロスペクションから生成された仮想リレーションフィールドのみがそれらに準拠しておらず、調整が必要でした)。これにより、生成されたPrisma Client APIのエルゴノミクスが最適化されます。
カスタムモデル名とフィールド名の使用
しかし、Prisma Client APIで公開されるカラム名やテーブル名にさらに変更を加えたい場合があります。一般的な例として、データベーススキーマでよく使用されるsnake_case記法を、JavaScript/TypeScript開発者にとってより自然に感じられるPascalCaseやcamelCase記法に変換することが挙げられます。
snake_case記法に基づいた、イントロスペクションから取得した以下のモデルを仮定します
model my_user {
user_id Int @id @default(sequence())
first_name String?
last_name String @unique
}
このモデル用にPrisma Client APIを生成した場合、そのAPIではsnake_case記法が使用されます
const user = await prisma.my_user.create({
data: {
first_name: 'Alice',
last_name: 'Smith',
},
})
Prisma Client APIでデータベースのテーブル名やカラム名を使用したくない場合は、@mapおよび@@mapで設定できます
model MyUser {
userId Int @id @default(sequence()) @map("user_id")
firstName String? @map("first_name")
lastName String @unique @map("last_name")
@@map("my_user")
}
このアプローチにより、モデルとそのフィールドを自由に命名し、@map(フィールド名用)と@@map(モデル名用)を使用して、基になるテーブルとカラムを参照させることができます。Prisma Client APIは次のようになります
const user = await prisma.myUser.create({
data: {
firstName: 'Alice',
lastName: 'Smith',
},
})
Prisma Client APIの構成ページで、これについて詳しく学ぶことができます。